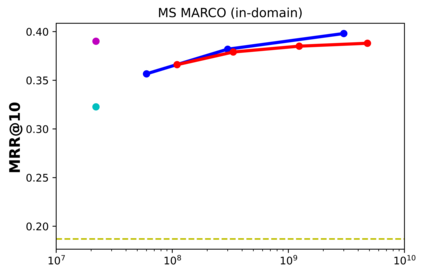
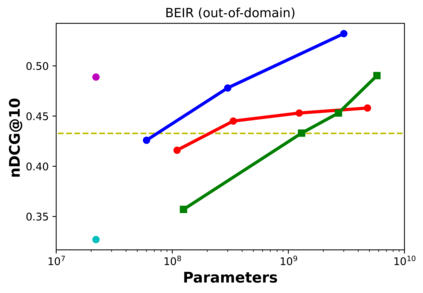
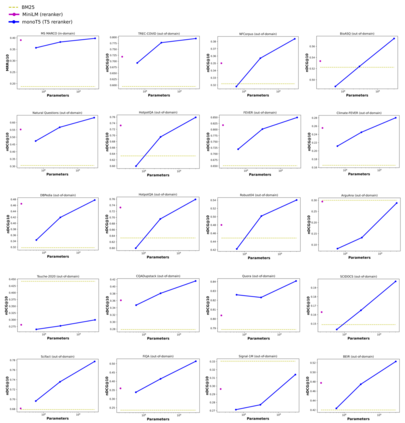
Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
翻译:最近的工作表明,小蒸馏语言模型对于规模较大、在广泛的信息检索任务中规模较大、速度较慢的模型来说,是强大的竞争者。这在一系列信息检索任务中成为蒸馏和密集的模型,由于潜伏限制,在现实世界检索应用程序中选择部署。在这项工作中,我们质疑这种做法,显示参数的数量和早期查询文件互动在检索模型的普及能力中起着重要作用。我们的实验表明,不断增大的模型规模导致在内部测试组中取得边际收益,但在微调期间从未看到的新领域获得更大的收益。此外,我们还表明,重新排序的模型在几项任务中大大超过类似规模的密集模型。我们最大的重新排序器在基准-IR(BEIIR)18个数据集中的12个中达到了最新状态,超过以往的艺术状态,平均点为3个。最后,我们确认,在多哈的效力并不是零发效果的良好指标。代码可在https://github.com/guilheremr04/scaling-zerierie.co上查阅。