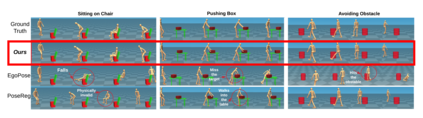
We propose a method for incorporating object interaction and human body dynamics into the task of 3D ego-pose estimation using a head-mounted camera. We use a kinematics model of the human body to represent the entire range of human motion, and a dynamics model of the body to interact with objects inside a physics simulator. By bringing together object modeling, kinematics modeling, and dynamics modeling in a reinforcement learning (RL) framework, we enable object-aware 3D ego-pose estimation. We devise several representational innovations through the design of the state and action space to incorporate 3D scene context and improve pose estimation quality. We also construct a fine-tuning step to correct the drift and refine the estimated human-object interaction. This is the first work to estimate a physically valid 3D full-body interaction sequence with objects (e.g., chairs, boxes, obstacles) from egocentric videos. Experiments with both controlled and in-the-wild settings show that our method can successfully extract an object-conditioned 3D ego-pose sequence that is consistent with the laws of physics.
翻译:我们提出了一个将物体相互作用和人体动态纳入三维自我定位任务的方法。 我们用一个头顶相机将物体相互作用和人体动态纳入三维自我定位任务中。 我们使用人体运动的运动模型来代表整个人类运动, 和身体的动态模型来与物理模拟器中的物体互动。 通过将物体模型、 运动模型和动态模型结合到一个强化学习( RL)框架中, 我们使得能够进行物体认识三维自我定位估计。 我们通过设计州和行动空间设计设计设计设计了几种代表创新, 以纳入三维场景环境, 并提高了外观估计质量。 我们还设计了一个微调步骤来纠正漂移, 并改进估计的人体- 对象互动。 这是根据以自我为中心的视频对物体( 例如椅子、 箱、 障碍) 进行物理上有效的三维全体互动序列的首项工作。 与受控物体和边缘环境的实验表明, 我们的方法可以成功地提取出一个符合物理学法则的、 3D自我定位序列。