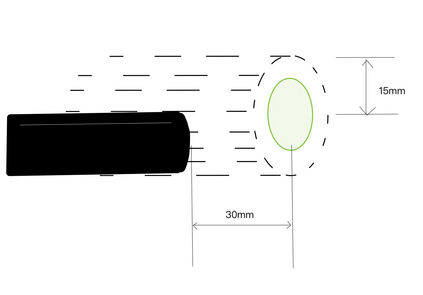
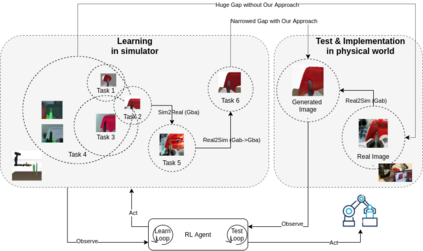
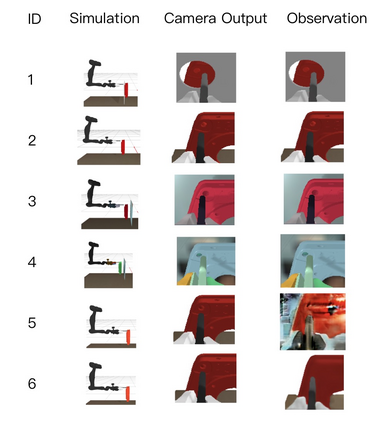
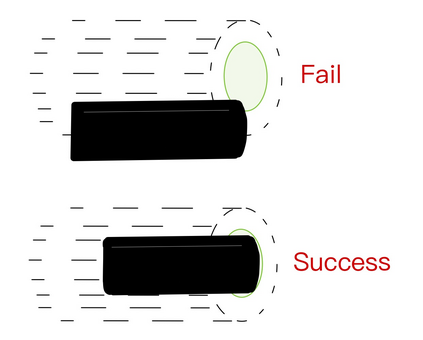
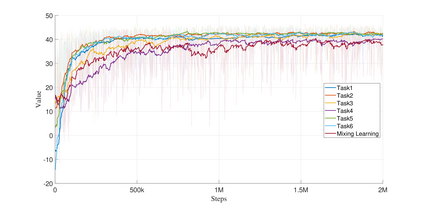
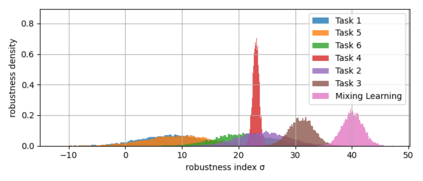
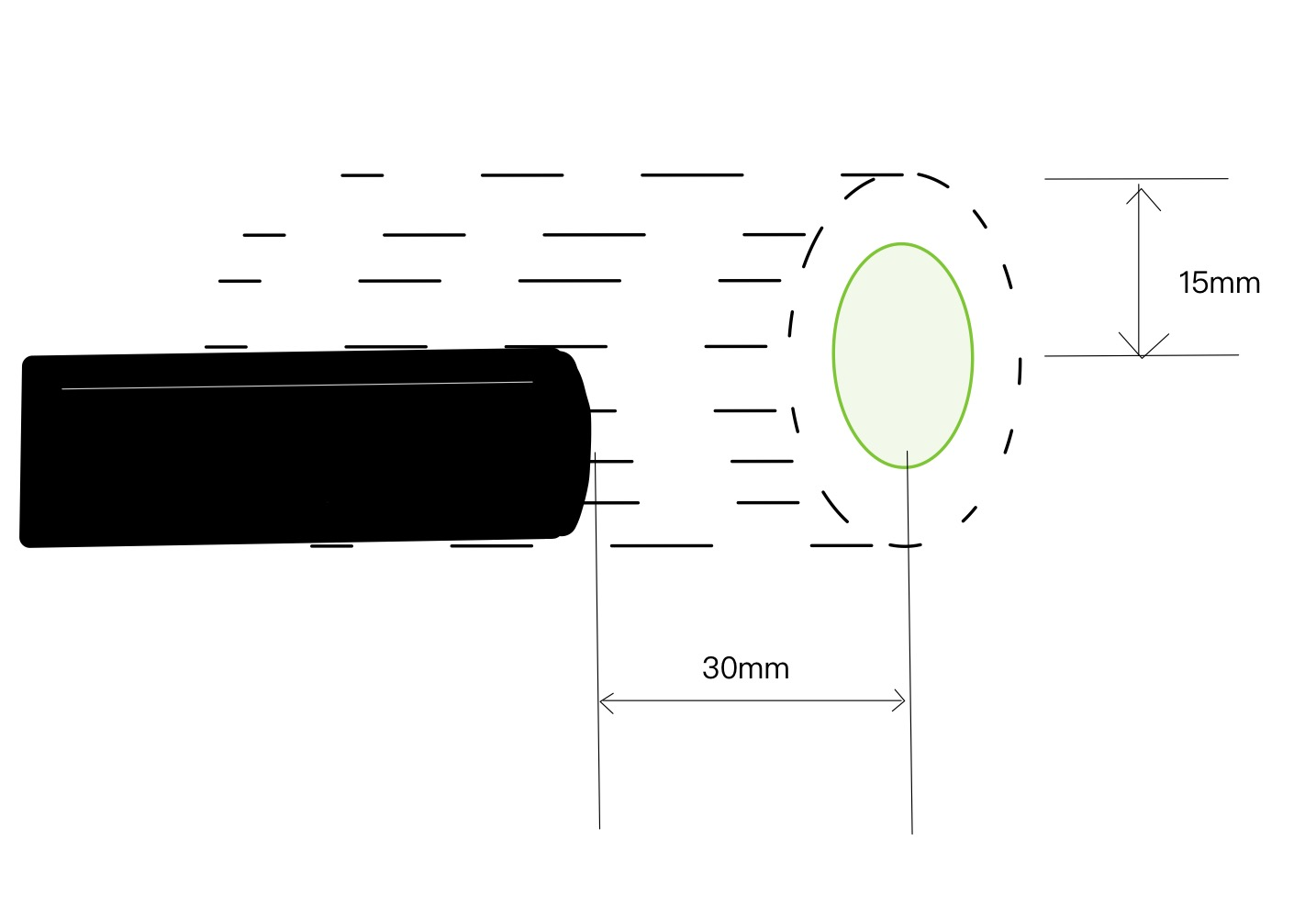
Reinforcement learning has shown a wide usage in robotics tasks, such as insertion and grasping. However, without a practical sim2real strategy, the policy trained in simulation could fail on the real task. There are also wide researches in the sim2real strategies, but most of those methods rely on heavy image rendering, domain randomization training, or tuning. In this work, we solve the insertion task using a pure visual reinforcement learning solution with minimum infrastructure requirement. We also propose a novel sim2real strategy, Real2Sim, which provides a novel and easier solution in policy adaptation. We discuss the advantage of Real2Sim compared with Sim2Real.
翻译:强化学习在机器人任务(如插入和掌握)中表现出了广泛的应用,但是,如果没有实际的模拟战略,模拟培训的政策可能无法完成真正的任务。在模拟战略中也有广泛的研究,但大多数方法都依赖于重图像成像、域随机化培训或调试。在这项工作中,我们用纯视觉强化学习解决方案解决插入任务,并有最低限度的基础设施要求。我们还提出了一个新型的模拟战略(Real2Sim ), 它为政策适应提供了新颖和更容易的解决方案。我们讨论了Real2Sim与Sim2Real的优势。