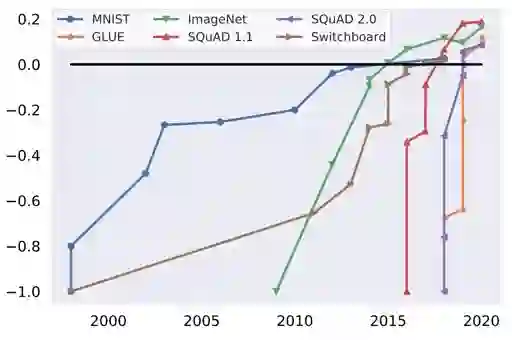
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
翻译:机器学习(ML)研究一般侧重于模型,而最突出的数据集被用于日常 ML 任务,而没有考虑到这些数据集的广度、难度和对根本问题的忠实性。 忽视数据集的根本重要性已经造成了一些重大问题,包括真实世界应用中的数据级联和以数据集驱动的标准对模型质量的饱和,从而阻碍了研究增长。 为了解决这个问题,我们提出了DataPerf,这是用于评估 ML 数据集和数据集工作算法的基准套件。 我们打算让培训组能够帮助评估相同问题的测试组,反之亦然。 这种反馈驱动战略将产生良性循环,加速以数据为中心的AI的开发。 刚德康门协会将维护DataPerf 。