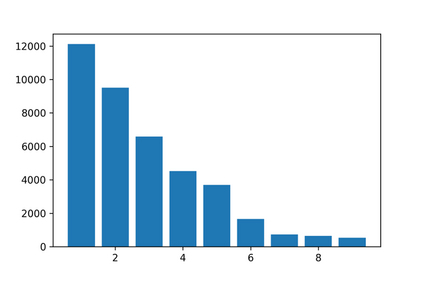
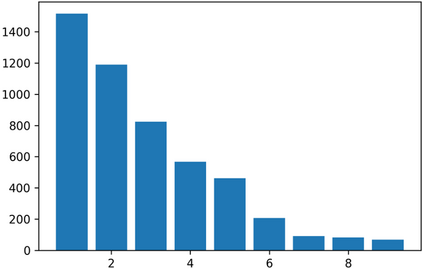
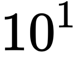The last decade has witnessed a prosperous development of computational methods and dataset curation for AI-aided drug discovery (AIDD). However, real-world pharmaceutical datasets often exhibit highly imbalanced distribution, which is largely overlooked by the current literature but may severely compromise the fairness and generalization of machine learning applications. Motivated by this observation, we introduce ImDrug, a comprehensive benchmark with an open-source Python library which consists of 4 imbalance settings, 11 AI-ready datasets, 54 learning tasks and 16 baseline algorithms tailored for imbalanced learning. It provides an accessible and customizable testbed for problems and solutions spanning a broad spectrum of the drug discovery pipeline such as molecular modeling, drug-target interaction and retrosynthesis. We conduct extensive empirical studies with novel evaluation metrics, to demonstrate that the existing algorithms fall short of solving medicinal and pharmaceutical challenges in the data imbalance scenario. We believe that ImDrug opens up avenues for future research and development, on real-world challenges at the intersection of AIDD and deep imbalanced learning.
翻译:在过去十年里,为AI辅助药物发现(AIDD)的计算方法和数据集整理工作取得了繁荣的发展。然而,现实世界制药数据集的分布往往高度不平衡,目前文献大都忽略了这一点,但可能会严重损害机器学习应用的公平和普遍化。我们以这一观察为动力,引入了ImDrug,这是一个综合基准,拥有开放源码的Python图书馆,由4个不平衡设置、11个AI准备数据集、54个学习任务和16个为不平衡学习量身定制的基线算法组成。它为跨越药物发现管道的广泛问题和解决办法,例如分子建模、药物目标互动和反向合成提供了方便和可定制的测试台。我们用新的评价指标进行了广泛的实证研究,以证明现有的算法没有解决数据不平衡情况下的药物和药物挑战。我们认为,IMDrug为未来研究与发展开辟了道路,揭示了在AID的交叉点和深刻的不平衡学习中的现实世界挑战。