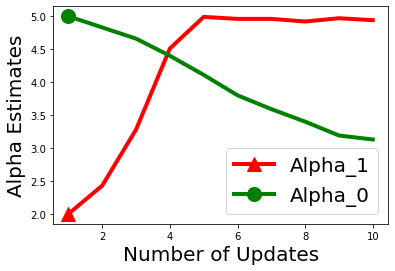
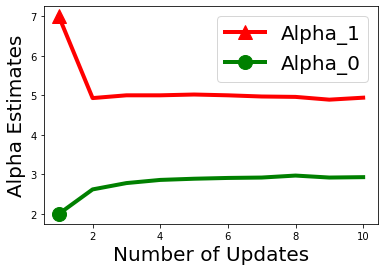
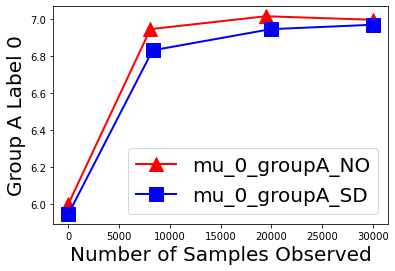
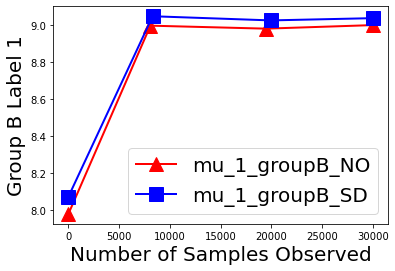
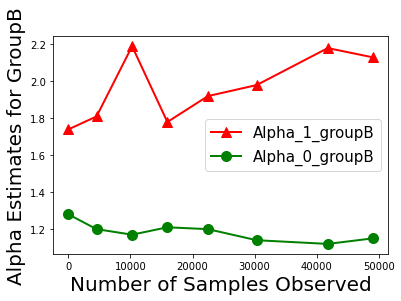
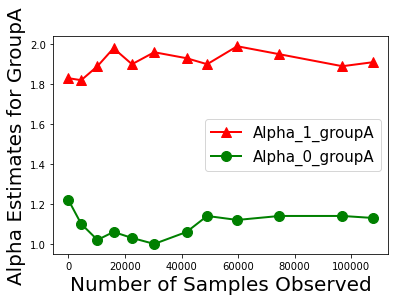
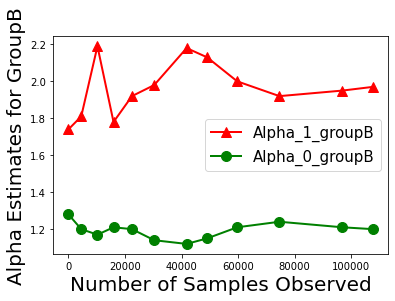
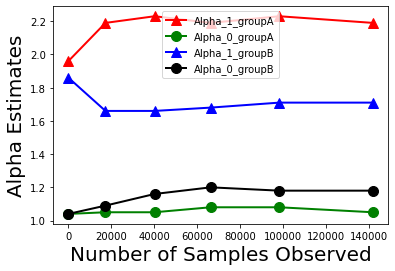
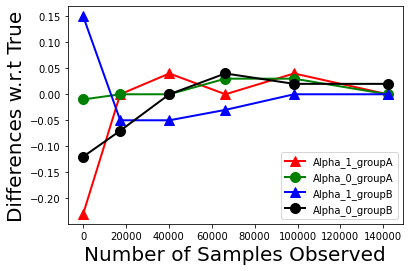
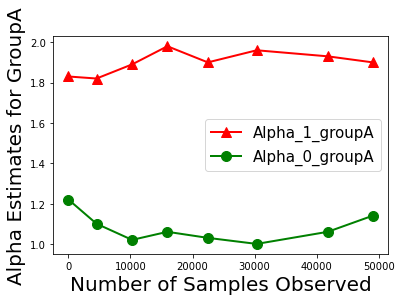
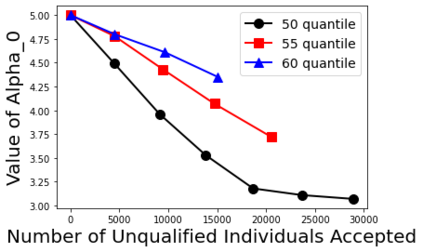
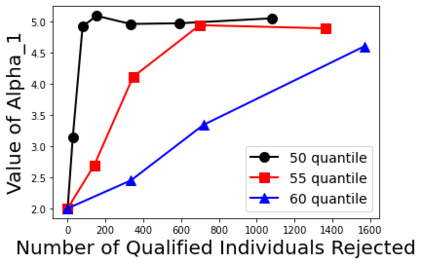
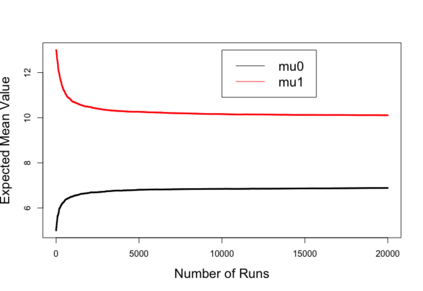
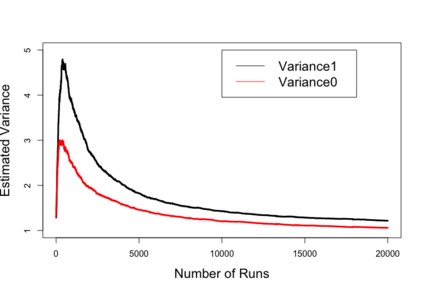
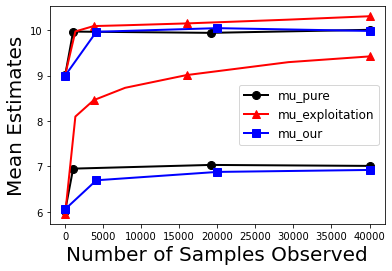
Biases in existing datasets used to train algorithmic decision rules can raise ethical, societal, and economic concerns due to the resulting disparate treatment of different groups. We propose an algorithm for sequentially debiasing such datasets through adaptive and bounded exploration. Exploration in this context means that at times, and to a judiciously-chosen extent, the decision maker deviates from its (current) loss-minimizing rule, and instead accepts some individuals that would otherwise be rejected, so as to reduce statistical data biases. Our proposed algorithm includes parameters that can be used to balance between the ultimate goal of removing data biases -- which will in turn lead to more accurate and fair decisions, and the exploration risks incurred to achieve this goal. We show, both analytically and numerically, how such exploration can help debias data in certain distributions. We further investigate how fairness measures can work in conjunction with such data debiasing efforts.
翻译:用于培训算法决策规则的现有数据集中的比喻可能会引起道德、社会和经济关切,因为由此产生的不同对待不同群体的做法不同。 我们提出一种算法,通过适应性和约束性探索,按顺序贬低这些数据集。 在这方面的探索意味着,有时,并且明智地选择,决策者偏离其(当前)损失最小化规则,而是接受一些否则会被拒绝的个人,以减少统计数据偏差。我们提议的算法包括一些参数,这些参数可用来平衡消除数据偏差的最终目标 -- -- 这反过来又会导致更准确和公正的决定,以及实现这一目标的勘探风险。我们从分析和数字两方面表明,这种探索如何在某些分布中帮助降低数据偏差。我们进一步调查公平措施如何与这种数据偏差努力相结合。