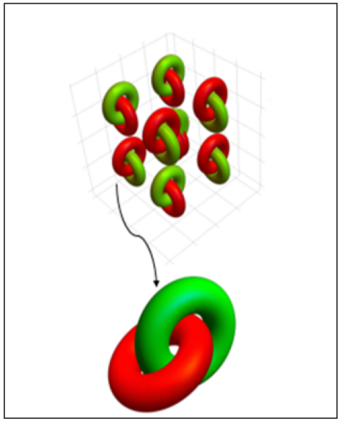
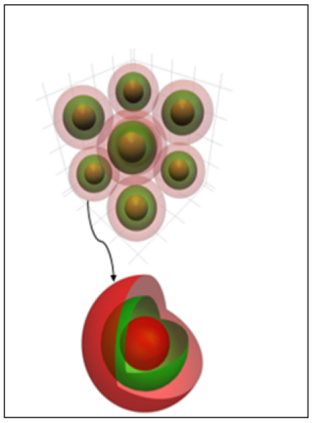
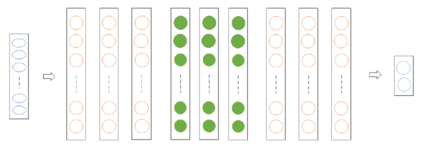
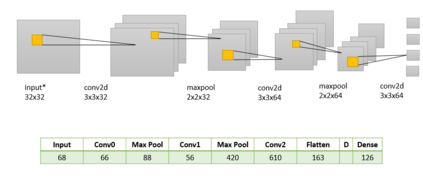
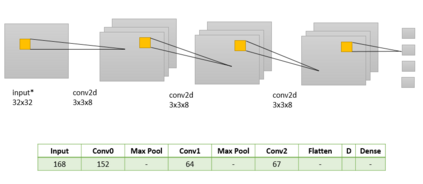
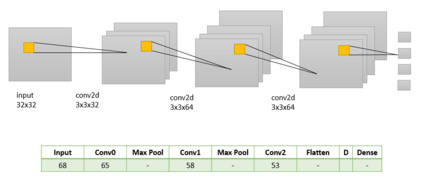
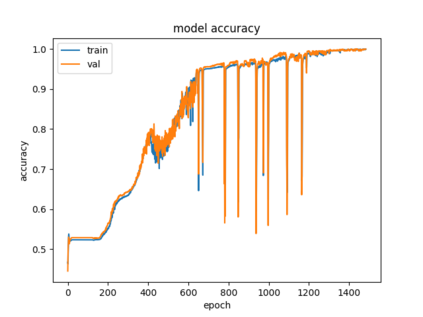
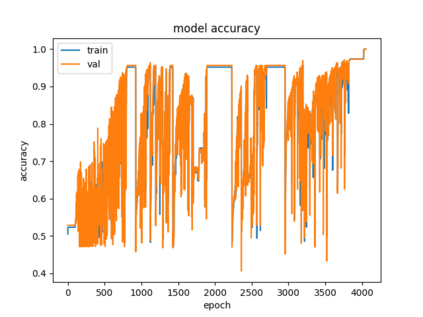
Success of deep neural networks in diverse tasks across domains of computer vision, speech recognition and natural language processing, has necessitated understanding the dynamics of training process and also working of trained models. Two independent contributions of this paper are 1) Novel activation function for faster training convergence 2) Systematic pruning of filters of models trained irrespective of activation function. We analyze the topological transformation of the space of training samples as it gets transformed by each successive layer during training, by changing the activation function. The impact of changing activation function on the convergence during training is reported for the task of binary classification. A novel activation function aimed at faster convergence for classification tasks is proposed. Here, Betti numbers are used to quantify topological complexity of data. Results of experiments on popular synthetic binary classification datasets with large Betti numbers(>150) using MLPs are reported. Results show that the proposed activation function results in faster convergence requiring fewer epochs by a factor of 1.5 to 2, since Betti numbers reduce faster across layers with the proposed activation function. The proposed methodology was verified on benchmark image datasets: fashion MNIST, CIFAR-10 and cat-vs-dog images, using CNNs. Based on empirical results, we propose a novel method for pruning a trained model. The trained model was pruned by eliminating filters that transform data to a topological space with large Betti numbers. All filters with Betti numbers greater than 300 were removed from each layer without significant reduction in accuracy. This resulted in faster prediction time and reduced memory size of the model.
翻译:在计算机愿景、语音识别和自然语言处理等不同领域,深心神经网络取得成功,这需要理解培训过程的动态动态,并使用经过培训的模式。本文的两种独立贡献是:(1) 用于更快培训趋同的新启动功能;(2) 系统处理经过培训的模型过滤器,而不论其激活功能如何。我们分析培训过程中每一层变化的培训样本空间的地形变化,改变激活功能。报告培训期间不断变化的激活功能对合并作用的影响,以进行二元分类。提议了一个旨在加快分类任务趋同的新启动功能。在这里,使用贝蒂数字来量化数据表层复杂性。报告了使用高贝蒂数字(>150)对广受欢迎的合成二进分类数据集的实验结果。结果显示,拟议的激活功能导致更快的趋同,要求以1.5至2的系数来减少其范围,因为贝蒂数字比拟议的激活功能更快。拟议的方法在基准图像数据集上得到验证:MNIST、CIFAR-10和CT-V-I的精确度。使用经过培训的大规模缩缩略数据,通过我们所培训的缩缩的缩缩缩的图像,用B的缩略图,通过S-B的缩略图的缩略图。