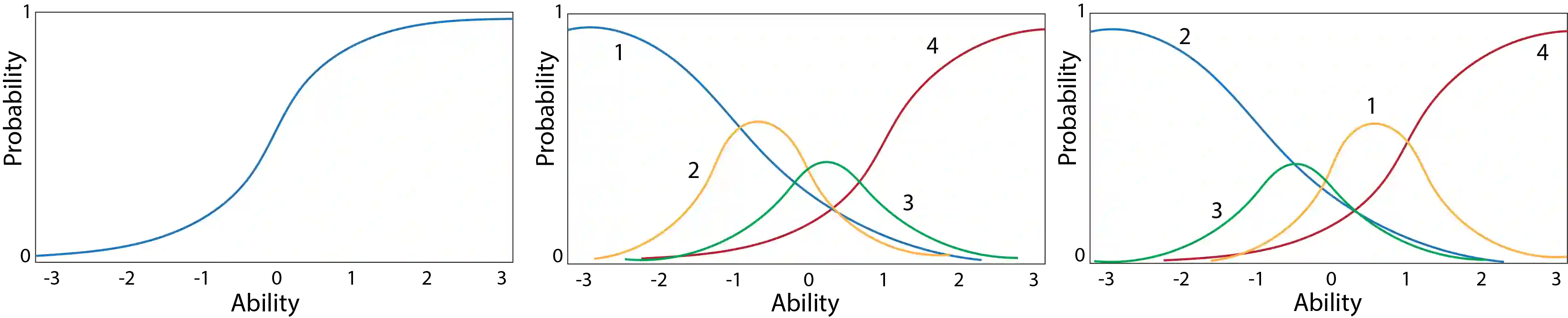
Most datasets suffer from partial or complete missing values, which has downstream limitations on the available models on which to test the data and on any statistical inferences that can be made from the data. Several imputation techniques have been designed to replace missing data with stand in values. The various approaches have implications for calculating clinical scores, model building and model testing. The work showcased here offers a novel means for categorical imputation based on item response theory (IRT) and compares it against several methodologies currently used in the machine learning field including k-nearest neighbors (kNN), multiple imputed chained equations (MICE) and Amazon Web Services (AWS) deep learning method, Datawig. Analyses comparing these techniques were performed on three different datasets that represented ordinal, nominal and binary categories. The data were modified so that they also varied on both the proportion of data missing and the systematization of the missing data. Two different assessments of performance were conducted: accuracy in reproducing the missing values, and predictive performance using the imputed data. Results demonstrated that the new method, Item Response Theory for Categorical Imputation (IRTCI), fared quite well compared to currently used methods, outperforming several of them in many conditions. Given the theoretical basis for the new approach, and the unique generation of probabilistic terms for determining category belonging for missing cells, IRTCI offers a viable alternative to current approaches.
翻译:多数数据集都存在部分或完全缺失的数值,这些数值对用于测试数据的可用模型和从数据中可以得出的任何统计推论都具有下游局限性。设计了几种估算技术,用数值立方体取代缺失的数据。各种方法对计算临床分数、模型构建和模型测试都有影响。此处展示的工作根据项目响应理论(IRT)为绝对估算提供了一种新的手段,并将其与机器学习领域目前使用的若干方法进行了比较,包括K-近邻(KNN),多重估算链式方程式(MICE)和亚马逊网络服务(AWS)深层学习方法(Datawig)。用三种不同的数据集进行了比较分析,这些数据集代表了圆形、名义和二元类别。对数据进行了修改,从而也根据数据缺失的数据生成比例和数据系统化进行了不同的评估。对业绩进行了两种不同的评估:复制缺失值的准确性,以及使用估算单元格的预测性能。结果表明,新的方法,即用于当前精确性分析的理论性理论性理论性,用于目前使用的多种理论性分析基础。