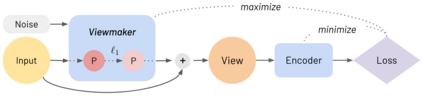
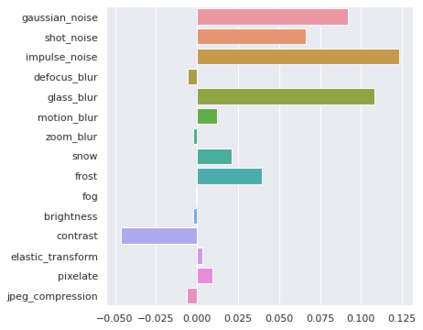
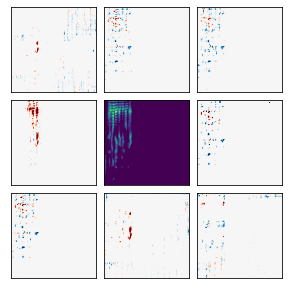
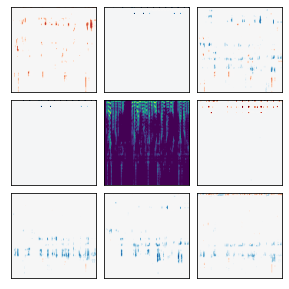
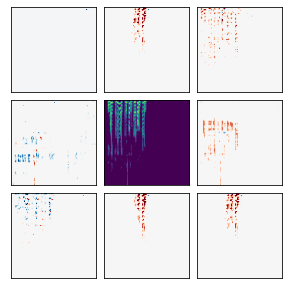
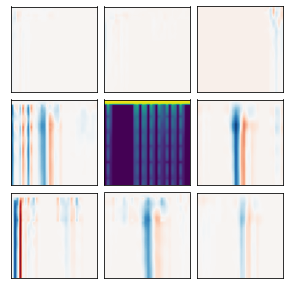
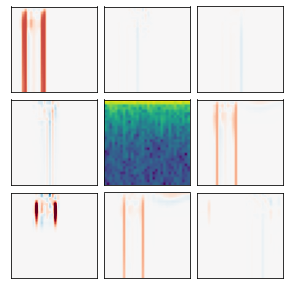
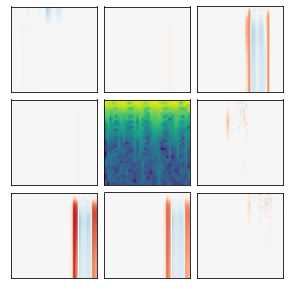
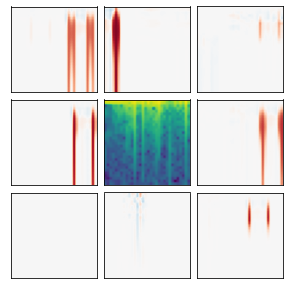
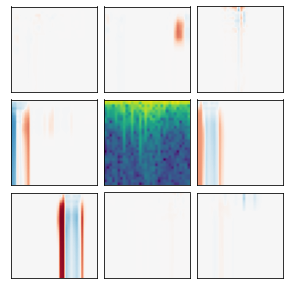
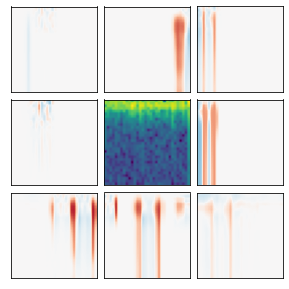
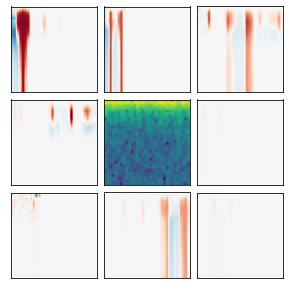
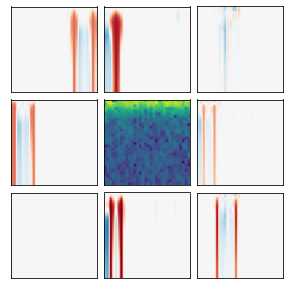
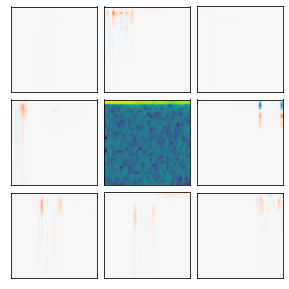
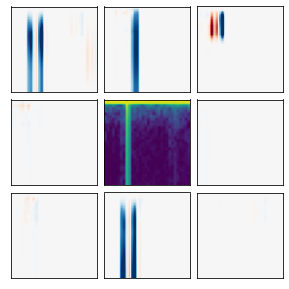
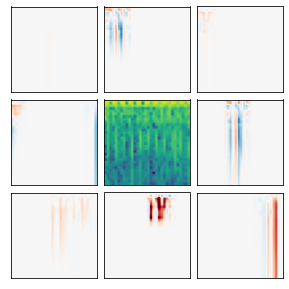
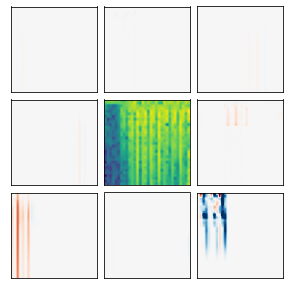
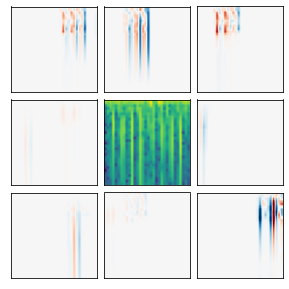
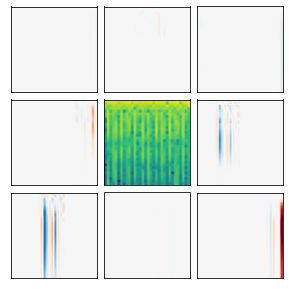
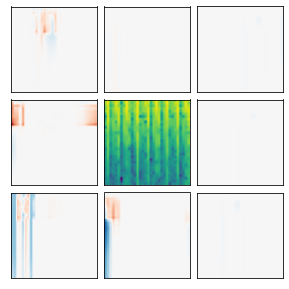
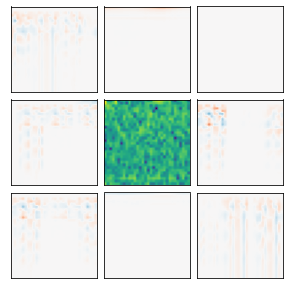
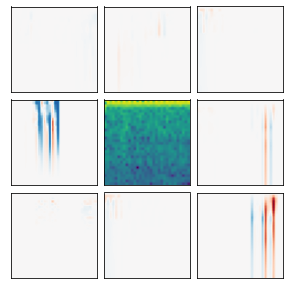
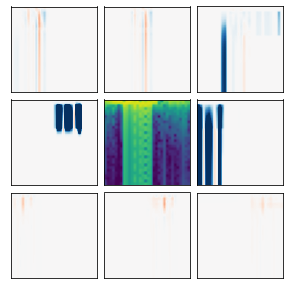
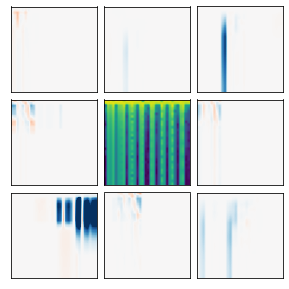
Many recent methods for unsupervised representation learning involve training models to be invariant to different "views," or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial $\ell_p$ perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.
翻译:近期许多未经监督的代表学习方法涉及培训模式,这些模式对不同的“观点”或投入的变换版本产生不同差异。然而,设计这些观点需要大量的人类专门知识和实验,从而阻碍广泛采用跨领域和模式的未经监督的代表学习方法。为了解决这个问题,我们建议了造型网络:能够学会为对比性学习产生依赖投入的观点的基因化模型。我们与一个编码网络联合培训这个网络,以产生对立的 $\ ell_ p$ perturbrbation 投入,产生富有挑战性但有用的观点,而没有广泛的人类调控。我们所了解的观点,在应用到CIFAR-10时,能够将相对的精确性传输到用于SimCLR模型的经过良好研究的增强的精确性。我们的观点大大超过语音(+9% 绝对值) 和可磨损传感器(+17% 绝对值) 中的基线增强性。我们还展示了如何将造型观点与手动的观点结合起来,以提高普通图像腐败的稳健性。我们的方法表明,所了解的观点是一种很有希望的方法,可以减少不需的专业知识和努力的学习的领域。