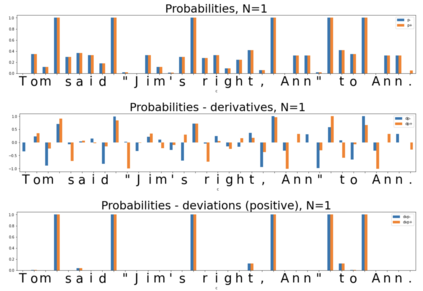
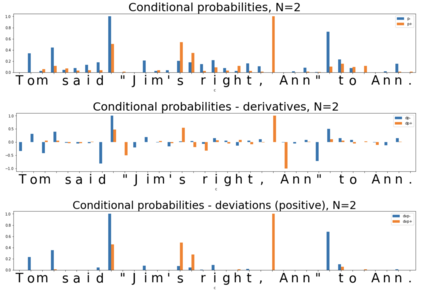
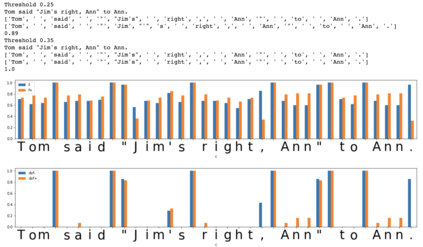
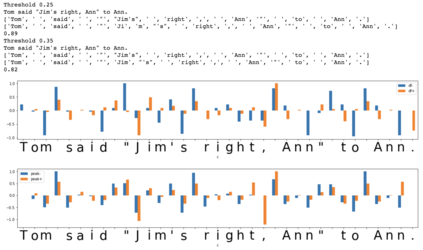
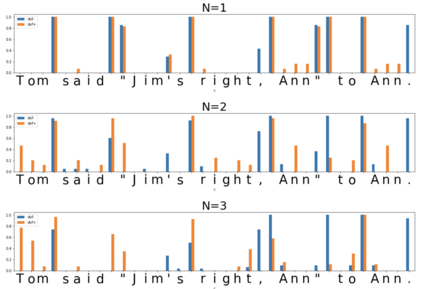
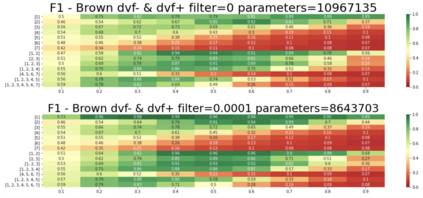
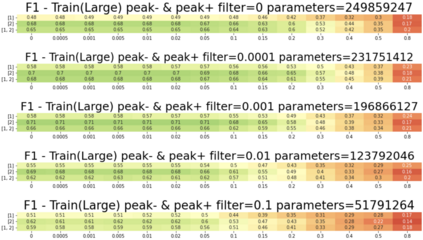
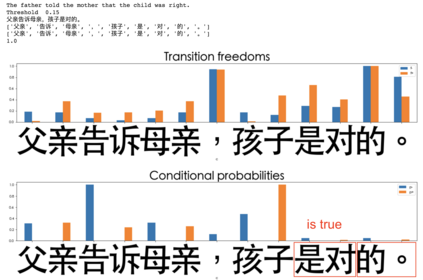
In the presented study, we discover that the so-called "transition freedom" metric appears superior for unsupervised tokenization purposes in comparison to statistical metrics such as mutual information and conditional probability, providing F-measure scores in range from $0.71$ to $1.0$ across explored multilingual corpora. We find that different languages require different offshoots of that metric (such as derivative, variance, and "peak values") for successful tokenization. Larger training corpora do not necessarily result in better tokenization quality, while compressing the models by eliminating statistically weak evidence tends to improve performance. The proposed unsupervised tokenization technique provides quality better than or comparable to lexicon-based ones, depending on the language.
翻译:在提交的研究报告中,我们发现,与诸如相互信息和有条件概率等统计指标相比,所谓的“过渡自由”指标似乎在未经监督的象征性化方面优于诸如相互信息和有条件概率等统计指标,在所探索的多语种公司之间提供了701美元至1美元之间的F度量计。 我们发现,不同的语言要求该指标的不同分支(如衍生物、差异和“峰值 ” ) 才能成功象征性化。 大型培训公司不一定能带来更好的象征性化质量,而通过消除统计上薄弱的证据来压缩模型则往往能提高性能。 拟议的未经监督的象征性化技术提供的质量优于或可与基于词汇的技术相比,取决于语言。