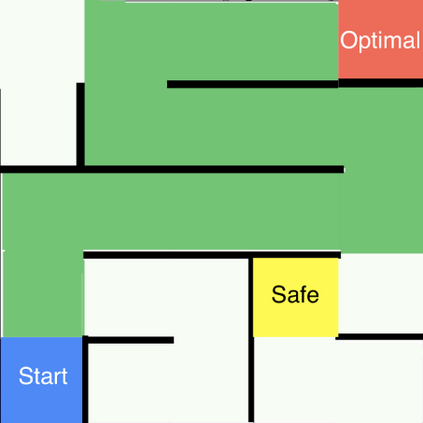
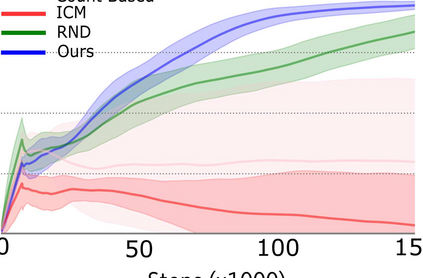
Reward shaping (RS) is a powerful method in reinforcement learning (RL) for overcoming the problem of sparse or uninformative rewards. However, RS typically relies on manually engineered shaping-reward functions whose construction is time-consuming and error-prone. It also requires domain knowledge which runs contrary to the goal of autonomous learning. We introduce Reinforcement Learning Optimising Shaping Algorithm (ROSA), an automated RS framework in which the shaping-reward function is constructed in a novel Markov game between two agents. A reward-shaping agent (Shaper) uses switching controls to determine which states to add shaping rewards and their optimal values while the other agent (Controller) learns the optimal policy for the task using these shaped rewards. We prove that ROSA, which easily adopts existing RL algorithms, learns to construct a shaping-reward function that is tailored to the task thus ensuring efficient convergence to high performance policies. We demonstrate ROSA's congenial properties in three carefully designed experiments and show its superior performance against state-of-the-art RS algorithms in challenging sparse reward environments.
翻译:奖励制成(RS)是强化学习的有力方法,用以克服稀有或无信息回报的问题。然而,塞族共和国通常依赖人工设计的塑造-奖励功能,其构建耗时且容易出错。它还要求有与自主学习目标相违背的域知识。我们引入了强化学习优化生成成形法(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA))(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)(ROSA)是一个自动框架,在两个代理商之间的新颖的Markov游戏中构建了塑造-奖励功能(ROL)(RL)(RL)(RL)(RL)(RL)(RL)(RS)(RP)(RP)(RAP)(RP)(REPer)(RE)(RE)(RA(RA)(RA)(RA)(RAD)(RAD)(RA)(RAD)(RA(RA)(RA)(RA)(RP)(RP)(RP)(RP)(R)(R)(RA(RP)(R)(RP)(RP)(R)(R)(R)(R)(R)(R)(R)(R)(RS(R)(RP)(R)(RP)(RP)(RP)(RP)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(RP)(RP)(R)(R)(RP)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(R)(