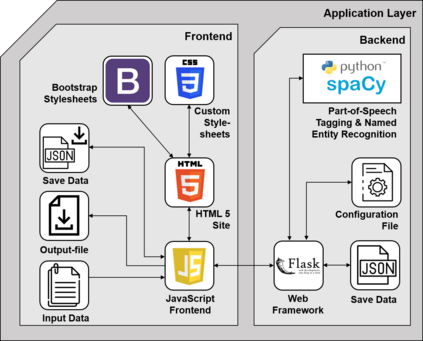
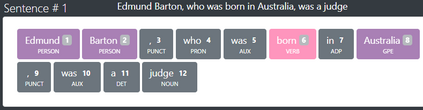
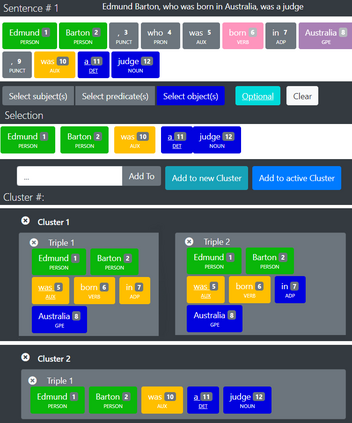
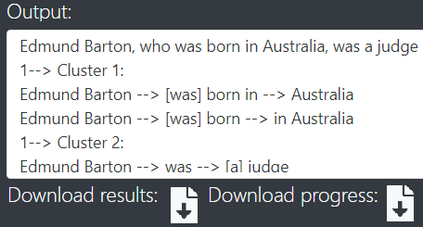
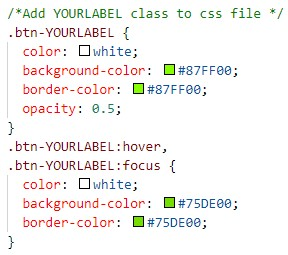
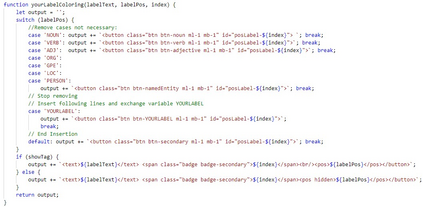
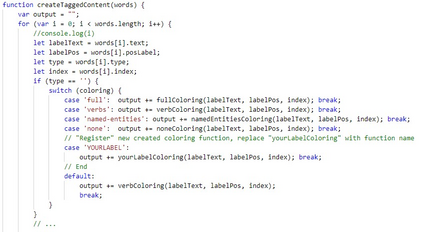
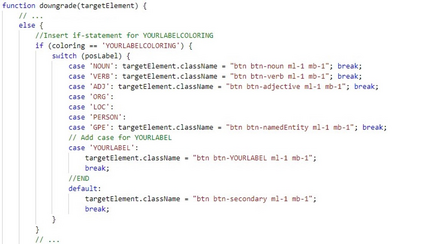
Open Information Extraction (OIE) is the task of extracting facts from sentences in the form of relations and their corresponding arguments in schema-free manner. Intrinsic performance of OIE systems is difficult to measure due to the incompleteness of existing OIE benchmarks: the ground truth extractions do not group all acceptable surface realizations of the same fact that can be extracted from a sentence. To measure performance of OIE systems more realistically, it is necessary to manually annotate complete facts (i.e., clusters of all acceptable surface realizations of the same fact) from input sentences. We propose AnnIE: an interactive annotation platform that facilitates such challenging annotation tasks and supports creation of complete fact-oriented OIE evaluation benchmarks. AnnIE is modular and flexible in order to support different use case scenarios (i.e., benchmarks covering different types of facts). We use AnnIE to build two complete OIE benchmarks: one with verb-mediated facts and another with facts encompassing named entities. Finally, we evaluate several OIE systems on our complete benchmarks created with AnnIE. Our results suggest that existing incomplete benchmarks are overly lenient, and that OIE systems are not as robust as previously reported. We publicly release AnnIE under non-restrictive license.
翻译:开放信息提取系统(OIE)的任务是从各种关系及其相应论据中从判决中以无计划方式提取事实。由于OIE现有基准不完整,OIE系统的内在性能难以测量:地面真相提取没有将从句子中提取的相同事实的所有可接受的表面实现情况归为一组。为了更现实地衡量OIE系统的表现,有必要从输入句子中手工对完整事实进行批注(即所有可接受的对同一事实的表面认识组)。我们建议ANIE:一个互动说明平台,为这种挑战性说明任务提供便利,并支持建立完整的面向事实的OIEE评价基准。ANIE是模块和灵活的,以支持不同的使用案例情景(即涵盖不同类型事实的基准 ) 。我们用ANIE建立两个完整的基准:一个带有verb调解事实,另一个包含被命名实体的事实。最后,我们评估了与ANIE共同创建的完整基准的若干OIE系统。我们的结果表明,现有的不完全的基准过于宽松,我们以前报告的OIEEA系统是不可靠的。