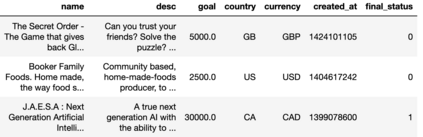
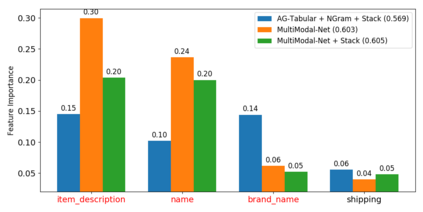
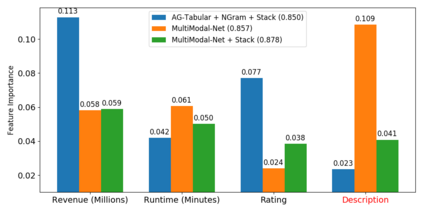
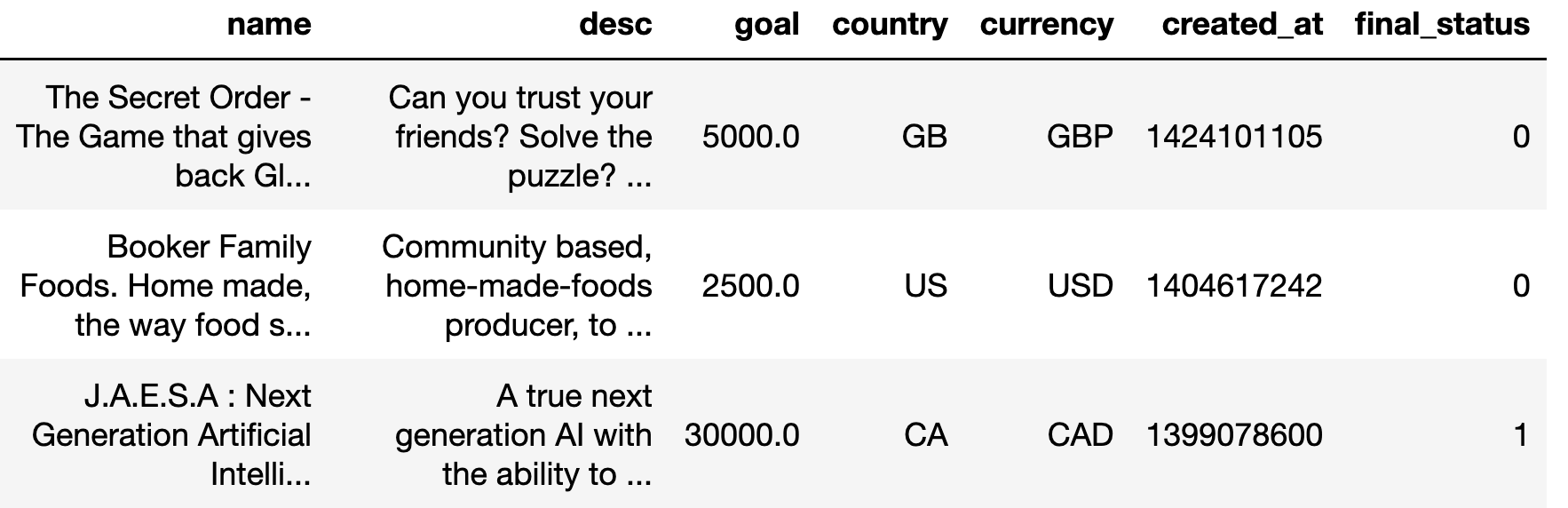
We consider the use of automated supervised learning systems for data tables that not only contain numeric/categorical columns, but one or more text fields as well. Here we assemble 18 multimodal data tables that each contain some text fields and stem from a real business application. Our publicly-available benchmark enables researchers to comprehensively evaluate their own methods for supervised learning with numeric, categorical, and text features. To ensure that any single modeling strategy which performs well over all 18 datasets will serve as a practical foundation for multimodal text/tabular AutoML, the diverse datasets in our benchmark vary greatly in: sample size, problem types (a mix of classification and regression tasks), number of features (with the number of text columns ranging from 1 to 28 between datasets), as well as how the predictive signal is decomposed between text vs. numeric/categorical features (and predictive interactions thereof). Over this benchmark, we evaluate various straightforward pipelines to model such data, including standard two-stage approaches where NLP is used to featurize the text such that AutoML for tabular data can then be applied. Compared with human data science teams, the fully automated methodology that performed best on our benchmark (stack ensembling a multimodal Transformer with various tree models) also manages to rank 1st place when fit to the raw text/tabular data in two MachineHack prediction competitions and 2nd place (out of 2380 teams) in Kaggle's Mercari Price Suggestion Challenge.
翻译:我们考虑对数据表格使用自动监督的学习系统,这些数据表格不仅包含数字/分类栏,而且包含一个或多个文本字段。在这里,我们收集了18个多式联运数据表格,每个表格包含一些文本字段,并源于真正的商业应用。我们公开提供的基准使研究人员能够全面评估他们自己的以数字、绝对和文本特征进行监督学习的方法。为了确保在所有18个数据集中运行良好的任何单一模型战略,将成为多式文本/图盘自动ML的实用基础,我们基准中的不同数据集在以下各方面差异很大:样本大小、问题类型(分类和回归任务的混合)、功能数量(文本列数在数据集之间为1至28不等),以及预测信号如何在文本与数字/分类特征(以及这些特征的预测性互动性)之间进行分解。除了这一基准外,我们还评估了用于模拟这些数据的各种直径直的管道,包括标准两阶段方法,即使用NLP来对文本进行编织,这样,AutMLML就可以对表格中的数据进行分类(分类和回归任务组合的组合)、挑战性数据数量(在数据集之间的1级之间有1至28页之间的文本列,并且将数据模型与人类数据模型与各种模型进行对比。