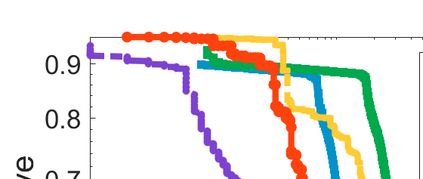
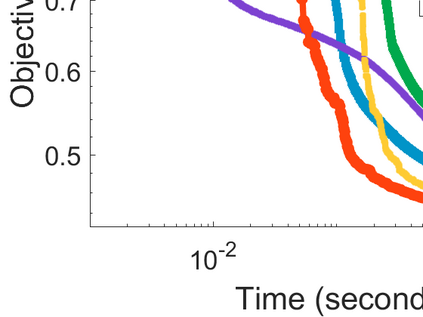
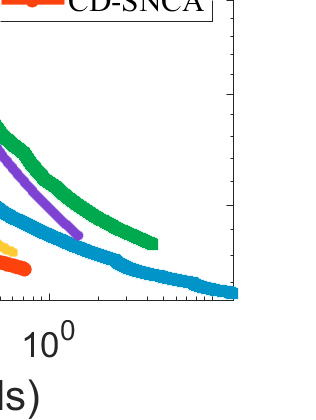
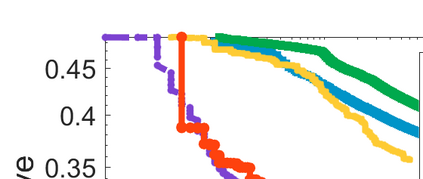
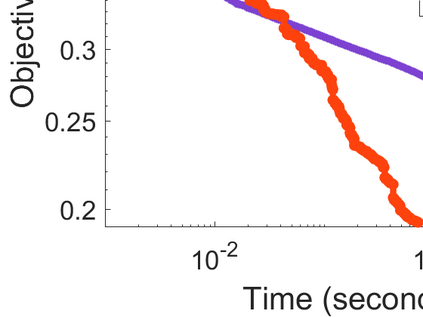
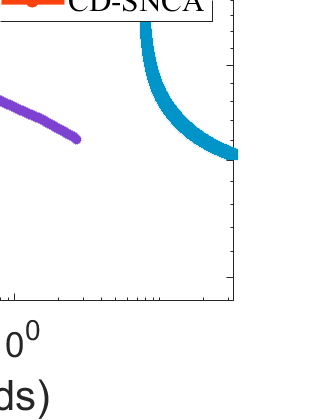
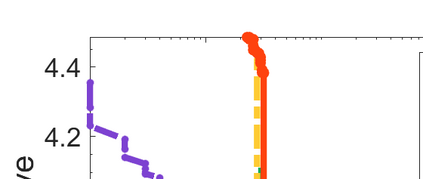
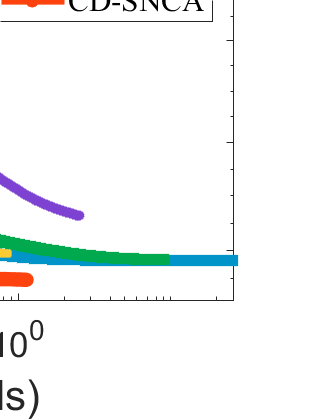
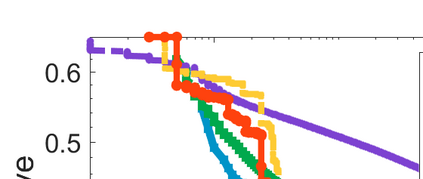
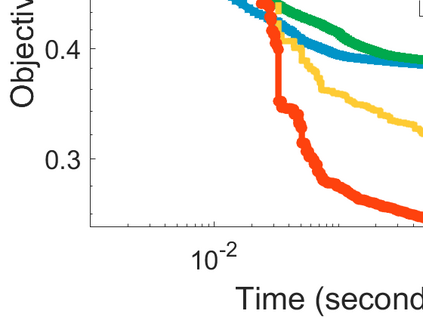
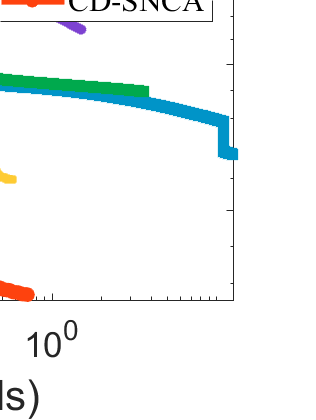
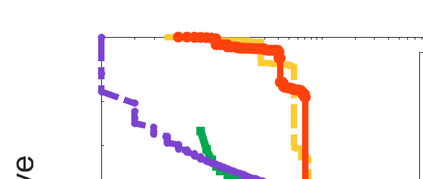
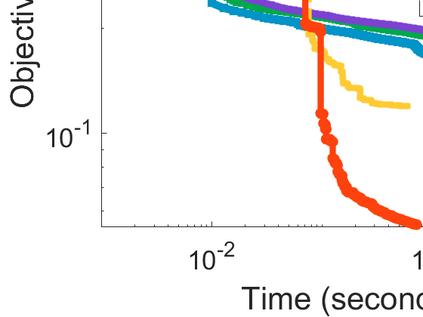
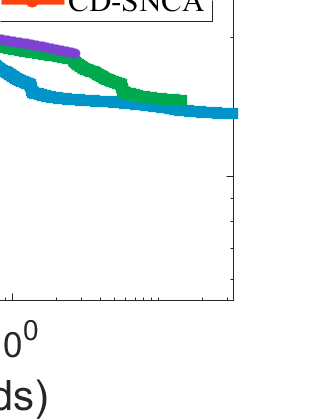
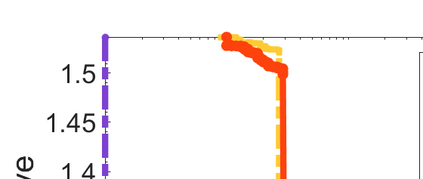
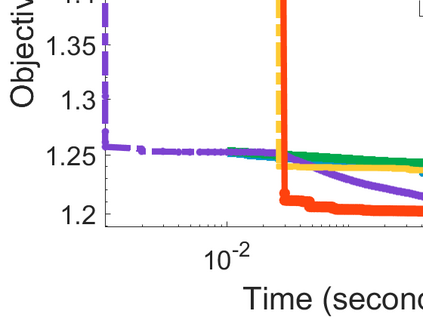
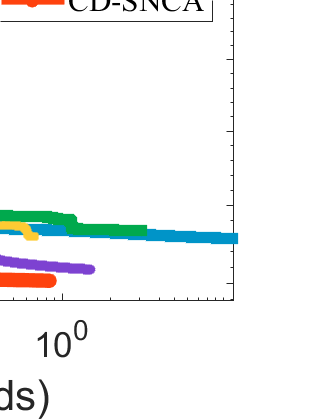
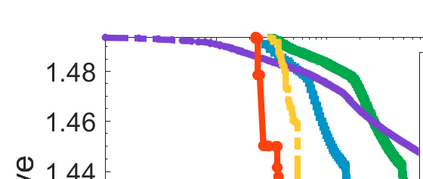
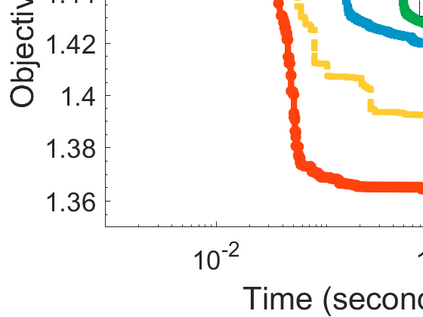
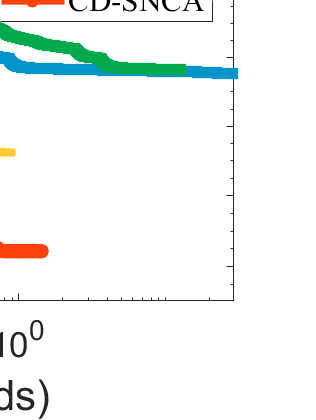
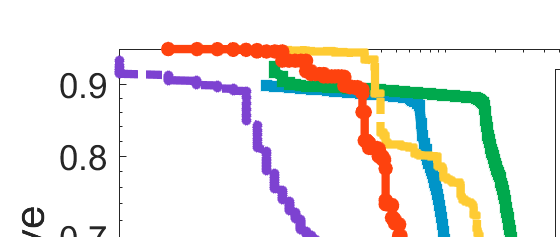
Difference-of-Convex (DC) minimization, referring to the problem of minimizing the difference of two convex functions, has been found rich applications in statistical learning and studied extensively for decades. However, existing methods are primarily based on multi-stage convex relaxation, only leading to weak optimality of critical points. This paper proposes a coordinate descent method for minimizing DC functions based on sequential nonconvex approximation. Our approach iteratively solves a nonconvex one-dimensional subproblem globally, and it is guaranteed to converge to a coordinate-wise stationary point. We prove that this new optimality condition is always stronger than the critical point condition and the directional point condition when the objective function is weakly convex. For comparisons, we also include a naive variant of coordinate descent methods based on sequential convex approximation in our study. When the objective function satisfies an additional regularity condition called \emph{sharpness}, coordinate descent methods with an appropriate initialization converge \emph{linearly} to the optimal solution set. Also, for many applications of interest, we show that the nonconvex one-dimensional subproblem can be computed exactly and efficiently using a breakpoint searching method. We present some discussions and extensions of our proposed method. Finally, we have conducted extensive experiments on several statistical learning tasks to show the superiority of our approach. Keywords: Coordinate Descent, DC Minimization, DC Programming, Difference-of-Convex Programs, Nonconvex Optimization, Sparse Optimization, Binary Optimization.
翻译:Convex (DC) 最小化差异, 指将两个 convex 函数的区别最小化的问题, 在统计学习中发现有丰富的应用,并进行了数十年的广泛研究。 但是, 现有方法主要基于多阶段 convex 放松, 只导致临界点的最佳性弱。 本文提出一个协调的下降方法, 以连续的非 convex 近似为基础, 将DC 函数最小化。 我们的方法反复解决一个非 convex 单维次问题, 并且保证会与一个协调的固定点汇合。 此外, 我们证明, 在目标函数弱化时, 新的最佳性条件总是比关键点条件和方向性点条件强。 为了比较, 我们还在研究中包含一个基于顺序的 convex 近似的基点的协调性下降方法。 当目标函数满足一个额外的常规性条件, 称为 \emph{sharrp}, 将下降方法与一个适当的初始化方法相协调 。 另外, 对于许多应用来说, 我们展示了非convex 的底平级方案的升级方法。