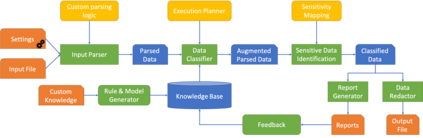
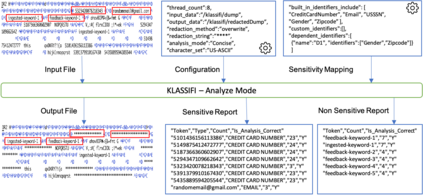
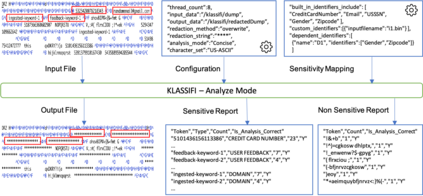
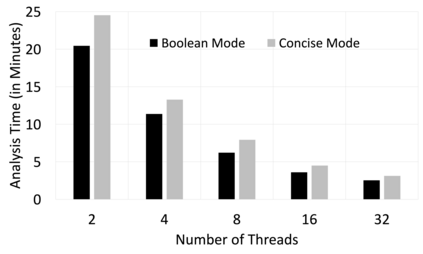
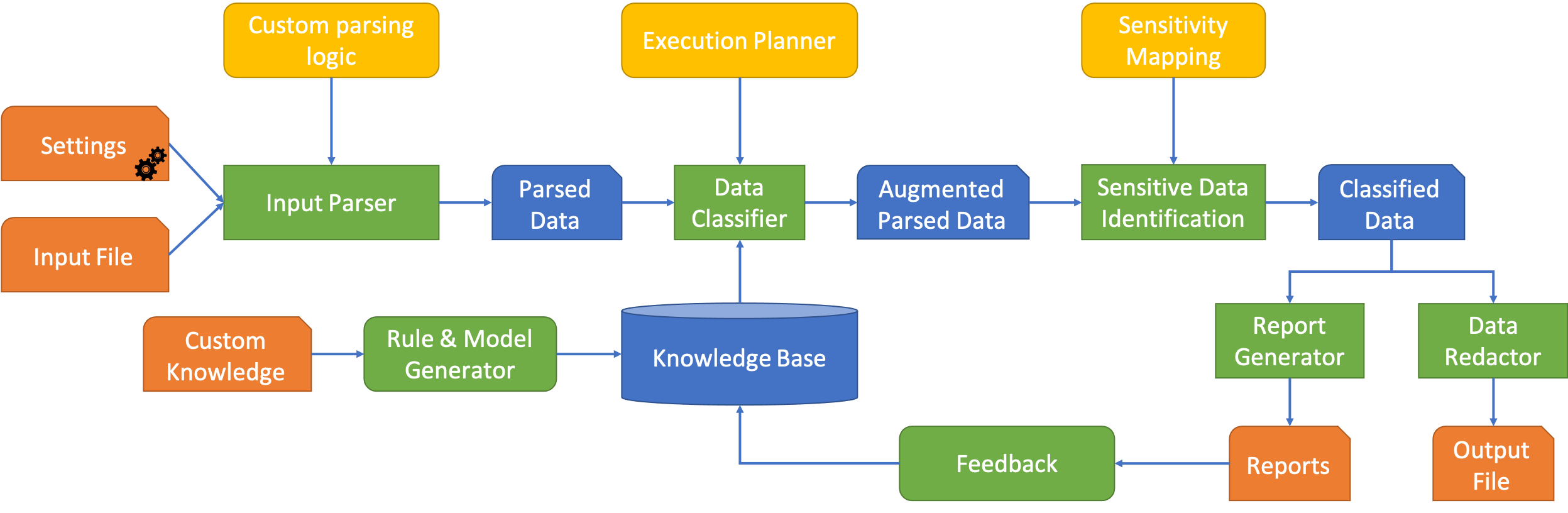
Diagnostic data such as logs and memory dumps from production systems are often shared with development teams to do root cause analysis of system crashes. Invariably such diagnostic data contains sensitive information and sharing it can lead to data leaks. To handle this problem we present Knowledge and Learning-based Adaptable System for Sensitive InFormation Identification and Handling (KLASSIFI) which is an end to end system capable of identifying and redacting sensitive information present in diagnostic data. KLASSIFI is highly customizable, allowing it to be used for various different business use cases by simply changing the configuration. KLASSIFI ensures that the output file is useful by retaining the metadata which is used by various debugging tools. Various optimizations have been done to improve the performance of KLASSIFI. Empirical evaluation of KLASSIFI shows that it is able to process large files (128 GB) in 84 minutes and its performance scales linearly with varying factors. This points to practicability of KLASSIFI
翻译:生产系统的日志和内存倾弃器等诊断性数据往往与开发团队共享,以便对系统崩溃进行根本原因分析,这类诊断性数据通常包含敏感信息,共享可能导致数据泄漏。为处理这一问题,我们推出了基于知识和学习的敏感化识别和处理可调适系统(KLASSIFI),这是能够识别和重编诊断数据中存在的敏感信息的终端系统(KLASSIFI)的终结系统。 KOSSSIFI具有高度自定义性,仅通过改变配置就可以用于不同业务使用案例。 KOSSSIFI确保输出文件有用,保留各种调试工具所使用的元数据。 已经做了各种优化,以改善 KASSIFI 的性能。 对 KLASSIFI 的实证评估表明,它能够在84分钟内处理大型文件(128GB),其性能尺度也以不同因素线性化。