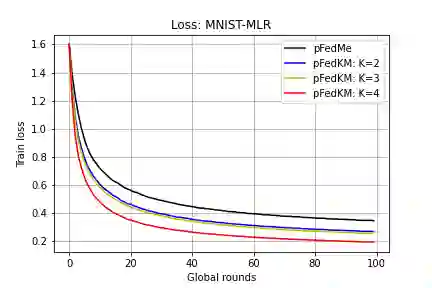
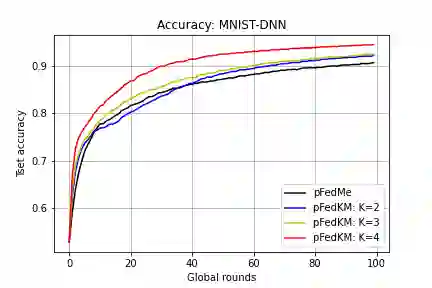
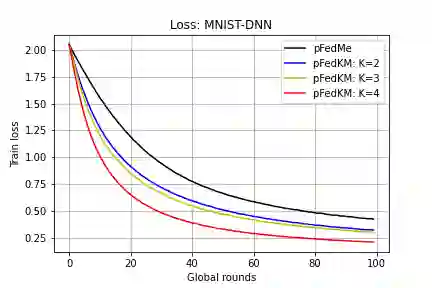
We study the recent emerging personalized federated learning (PFL) that aims at dealing with the challenging problem of Non-I.I.D. data in the federated learning (FL) setting. The key difference between PFL and conventional FL lies in the training target, of which the personalized models in PFL usually pursue a trade-off between personalization (i.e., usually from local models) and generalization (i.e., usually from the global model) on trained models. Conventional FL methods can hardly meet this target because of their both well-developed global and local models. The prevalent PFL approaches usually maintain a global model to guide the training process of local models and transfer a proper degree of generalization to them. However, the sole global model can only provide one direction of generalization and may even transfer negative effects to some local models when rich statistical diversity exists across multiple local datasets. Based on our observation, most real or synthetic data distributions usually tend to be clustered to some degree, of which we argue different directions of generalization can facilitate the PFL. In this paper, we propose a novel concept called clustered generalization to handle the challenge of statistical heterogeneity in FL. Specifically, we maintain multiple global (generalized) models in the server to associate with the corresponding amount of local model clusters in clients, and further formulate the PFL as a bi-level optimization problem that can be solved efficiently and robustly. We also conduct detailed theoretical analysis and provide the convergence guarantee for the smooth non-convex objectives. Experimental results on both synthetic and real datasets show that our approach surpasses the state-of-the-art by a significant margin.
翻译:我们研究了最近新出现的个人化联合会学习(PFL),其目的是处理非I.I.D.数据在联邦学习(FL)环境中的棘手问题。PFL和常规FL的关键区别在于培训目标,而PFL的个人化模式通常在个人化(通常来自当地模式)和一般化(通常来自全球模式)之间取舍(通常来自全球模式)之间取舍。常规FL方法由于全球和地方模式发展良好,很难达到这个目标。流行的非PFL方法通常维持一个全球模型,用以指导当地模型的平稳培训进程,并向其转移适当程度的通用化。然而,唯一的全球模型只能提供一个通用化方向,甚至可能在某些地方模型存在丰富的统计多样性(通常来自当地模式)和一般化(通常来自全球模式)之间进行权衡。根据我们的观察,大多数真实或合成数据分布往往会在一定程度上集中在一起,而我们则认为一般化的不同方向可以促进PFLFL。在这个文件中,我们建议一个创新的概念是,即,在高层次上,我们用多层次的分类化的分类化,我们用一个新的分类式的Floralalalalalalalalalalalalalalalalalalalalalal 来提出一个挑战。