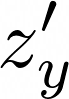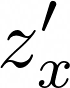In this work, we investigate an approach that relies on contrastive learning and music metadata as a weak source of supervision to train music representation models. Recent studies show that contrastive learning can be used with editorial metadata (e.g., artist or album name) to learn audio representations that are useful for different classification tasks. In this paper, we extend this idea to using playlist data as a source of music similarity information and investigate three approaches to generate anchor and positive track pairs. We evaluate these approaches by fine-tuning the pre-trained models for music multi-label classification tasks (genre, mood, and instrument tagging) and music similarity. We find that creating anchor and positive track pairs by relying on co-occurrences in playlists provides better music similarity and competitive classification results compared to choosing tracks from the same artist as in previous works. Additionally, our best pre-training approach based on playlists provides superior classification performance for most datasets.
翻译:暂无翻译