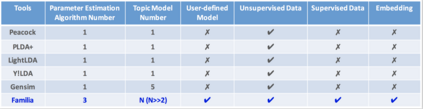
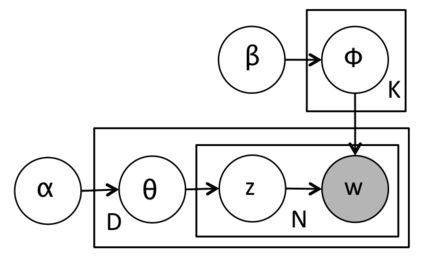
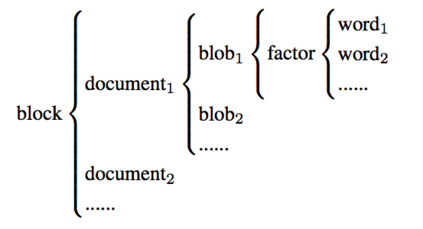
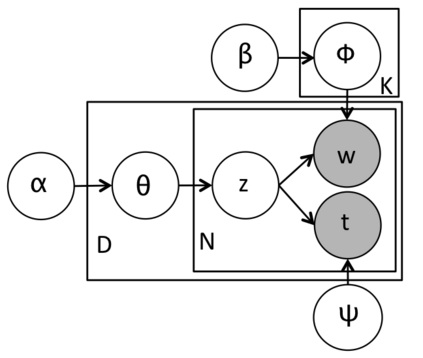
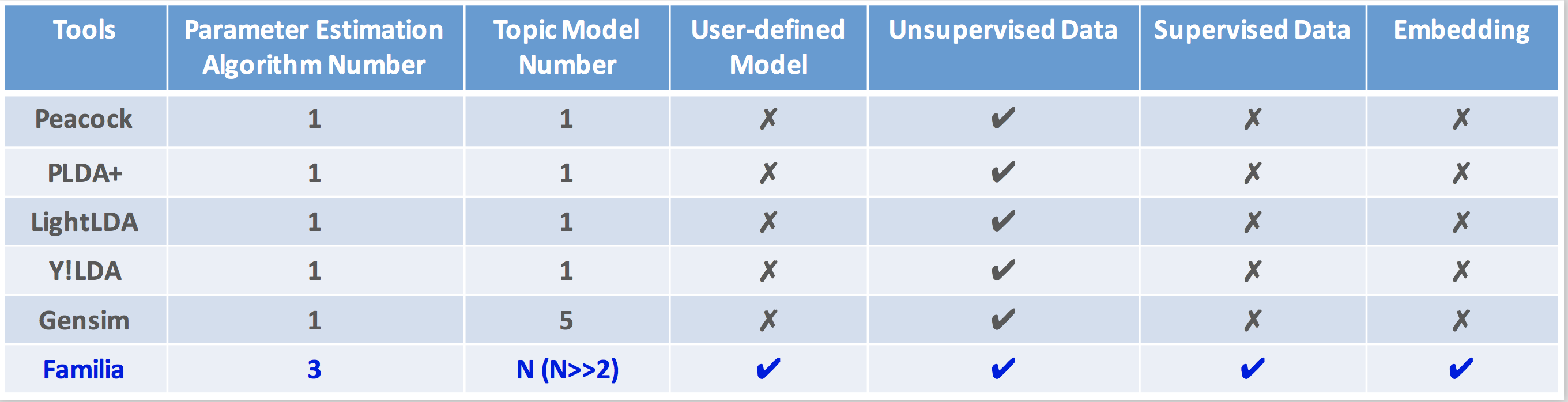
In the last decade, a variety of topic models have been proposed for text engineering. However, except Probabilistic Latent Semantic Analysis (PLSA) and Latent Dirichlet Allocation (LDA), most of existing topic models are seldom applied or considered in industrial scenarios. This phenomenon is caused by the fact that there are very few convenient tools to support these topic models so far. Intimidated by the demanding expertise and labor of designing and implementing parameter inference algorithms, software engineers are prone to simply resort to PLSA/LDA, without considering whether it is proper for their problem at hand or not. In this paper, we propose a configurable topic modeling framework named Familia, in order to bridge the huge gap between academic research fruits and current industrial practice. Familia supports an important line of topic models that are widely applicable in text engineering scenarios. In order to relieve burdens of software engineers without knowledge of Bayesian networks, Familia is able to conduct automatic parameter inference for a variety of topic models. Simply through changing the data organization of Familia, software engineers are able to easily explore a broad spectrum of existing topic models or even design their own topic models, and find the one that best suits the problem at hand. With its superior extendability, Familia has a novel sampling mechanism that strikes balance between effectiveness and efficiency of parameter inference. Furthermore, Familia is essentially a big topic modeling framework that supports parallel parameter inference and distributed parameter storage. The utilities and necessity of Familia are demonstrated in real-life industrial applications. Familia would significantly enlarge software engineers' arsenal of topic models and pave the way for utilizing highly customized topic models in real-life problems.
翻译:过去十年来,人们为文本工程提出了各种专题模型。然而,除了概率性边端语义分析(PLSA)和长端狄里赫莱分配(LDA)之外,大多数现有专题模型很少在工业情景中应用或考虑,这种现象是由于迄今为止支持这些专题模型的方便工具很少造成的。由于设计和实施参数推算算算法需要大量的专门知识和人力,软件工程师很容易简单地求助于PLSA/LDA,而没有考虑其手头问题是否合适。在本文件中,我们提出了一个可配置的、称为Familia(Family)的指数模型框架,以弥合学术研究成果和当前工业实践之间的巨大差距。家庭支持了一个重要的专题模型系列,这些模型在文本工程假设中广泛适用。为了减轻软件工程师在不熟悉Bayesian网络的情况下负担,家庭能够为各种专题模型进行自动参数推导论。通过改变数据结构,软件工程师能够很容易地探索现有专题模型的广泛范围,或者甚至设计其高清晰度的软件格式框架,从而在质量模型中找到一个更精确的模型。