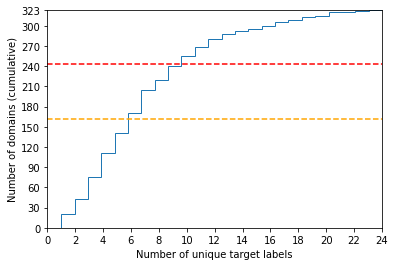
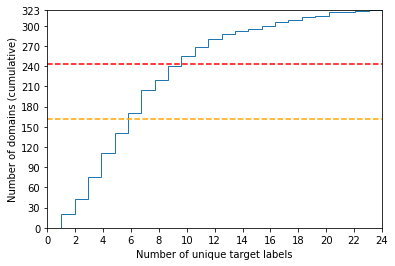
We share our experience with the recently released WILDS benchmark, a collection of ten datasets dedicated to developing models and training strategies which are robust to domain shifts. Several experiments yield a couple of critical observations which we believe are of general interest for any future work on WILDS. Our study focuses on two datasets: iWildCam and FMoW. We show that (1) Conducting separate cross-validation for each evaluation metric is crucial for both datasets, (2) A weak correlation between validation and test performance might make model development difficult for iWildCam, (3) Minor changes in the training of hyper-parameters improve the baseline by a relatively large margin (mainly on FMoW), (4) There is a strong correlation between certain domains and certain target labels (mainly on iWildCam). To the best of our knowledge, no prior work on these datasets has reported these observations despite their obvious importance. Our code is public.
翻译:我们与最近公布的WILDS基准分享了我们的经验。WILDS基准是10个数据集的集合,专门用于开发对域变强强的模型和培训战略。一些实验产生了一些关键观察,我们认为这些观察对今后关于WILDS的任何工作都具有普遍意义。我们的研究侧重于两个数据集:iWildCam和FMOW。我们显示:(1) 对每个评价指标分别进行交叉校验对对这两个数据集都至关重要,(2) 验证和测试性能之间薄弱的相互关系可能使iWildCam难以开发模型,(3) 超参数培训的微小变化使基准改善幅度相对较大(主要是FMOW),(4) 某些领域与某些目标标签(主要是iWildCam)之间有着密切的关联。据我们所知,尽管这些数据集显然重要,但先前没有报告过这些观察。我们的代码是公开的。