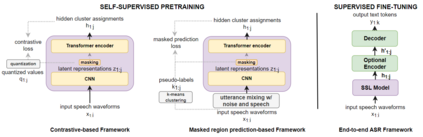
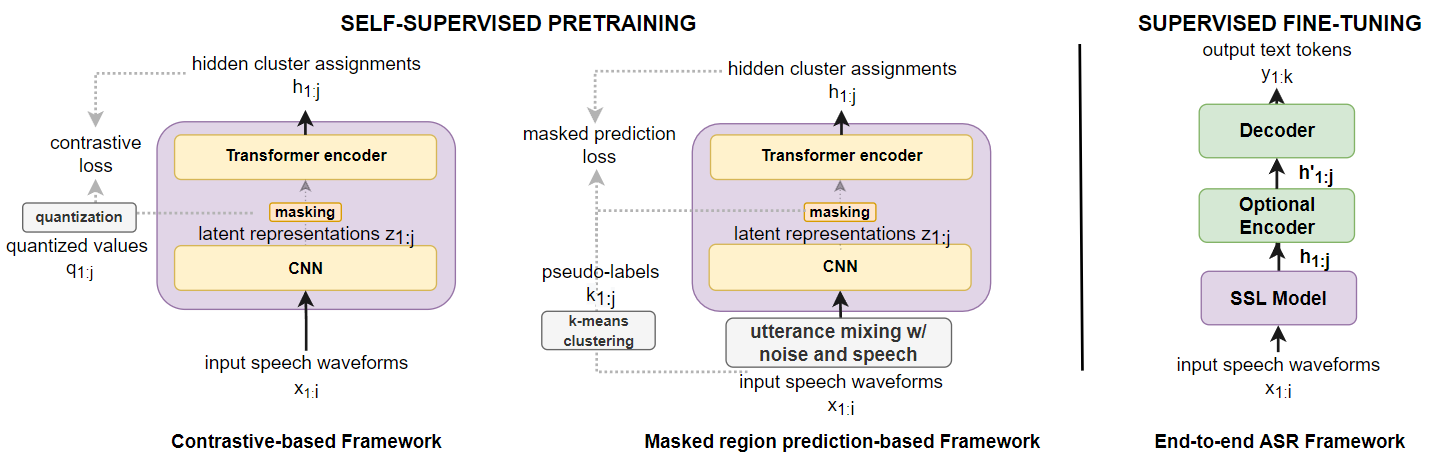
We investigate the performance of self-supervised pretraining frameworks on pathological speech datasets used for automatic speech recognition (ASR). Modern end-to-end models require thousands of hours of data to train well, but only a small number of pathological speech datasets are publicly available. A proven solution to this problem is by first pretraining the model on a huge number of healthy speech datasets and then fine-tuning it on the pathological speech datasets. One new pretraining framework called self-supervised learning (SSL) trains a network using only speech data, providing more flexibility in training data requirements and allowing more speech data to be used in pretraining. We investigate SSL frameworks such as the wav2vec 2.0 and WavLM models using different setups and compare their performance with different supervised pretraining setups, using two types of pathological speech, namely, Japanese electrolaryngeal and English dysarthric. Our results show that although SSL has shown success with minimally resourced healthy speech, we do not find this to be the case with pathological speech. The best supervised setup outperforms the best SSL setup by 13.9% character error rate in electrolaryngeal speech and 16.8% word error rate in dysarthric speech.
翻译:我们调查了用于自动语音识别的病理语言语音数据集自我监督的预培训框架的性能。现代端到端模型需要数千小时的数据才能进行良好的培训,但只有少量病理语言数据集可以公开提供。这个问题的一个证明解决办法是首先在大量健康语音数据集上对模型进行预先培训,然后在病理语言数据集上进行微调。一个称为自我监督学习(SSL)的新预培训框架仅用语音数据培训网络,在培训数据要求方面提供更大的灵活性,并允许在预培训中使用更多的语音数据。我们使用不同的设置来调查诸如Wav2vec 2.0和WavLM模型等SSL框架,并将其性能与不同监管的预培训设置进行比较,使用两种病理演讲类型,即日本电极和英语语调。我们的结果显示,虽然SSL在最少资源的健康演讲中表现出成功,但我们并不认为这属于病理学演讲的例子。我们使用最受监督的语音标注的语音比率为16.8%,而最佳的SLSLA值错误率是SLA16。