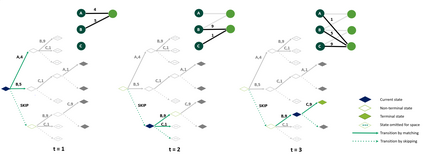
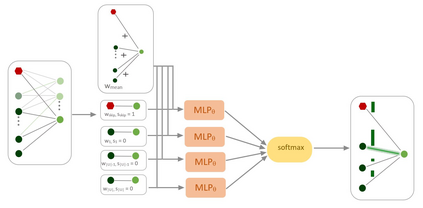
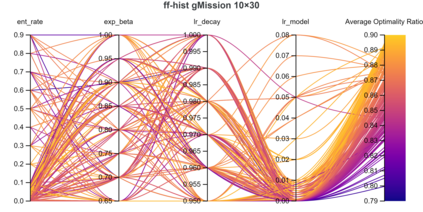
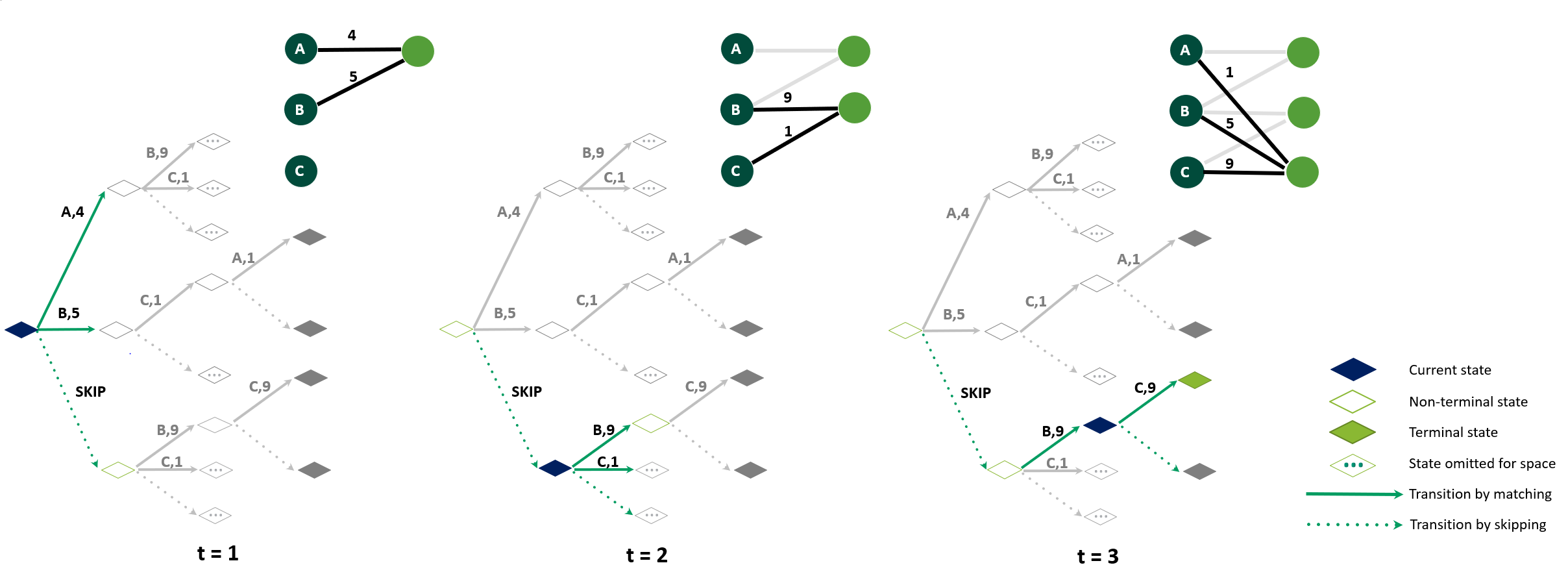
The challenge in the widely applicable online matching problem lies in making irrevocable assignments while there is uncertainty about future inputs. Most theoretically-grounded policies are myopic or greedy in nature. In real-world applications where the matching process is repeated on a regular basis, the underlying data distribution can be leveraged for better decision-making. We present an end-to-end Reinforcement Learning framework for deriving better matching policies based on trial-and-error on historical data. We devise a set of neural network architectures, design feature representations, and empirically evaluate them across two online matching problems: Edge-Weighted Online Bipartite Matching and Online Submodular Bipartite Matching. We show that most of the learning approaches perform consistently better than classical baseline algorithms on four synthetic and real-world datasets. On average, our proposed models improve the matching quality by 3-10% on a variety of synthetic and real-world datasets. Our code is publicly available at https://github.com/lyeskhalil/CORL.
翻译:广泛适用的在线匹配问题的挑战在于在未来投入不确定的情况下作出不可撤销的指定。 多数基于理论上的政策是短视的或贪婪的。 在经常重复匹配程序的实际应用中, 基本数据的分配可以用来更好地决策。 我们提出了一个端到端的强化学习框架, 以便根据历史数据的试验和测试得出更好的匹配政策。 我们设计了一套神经网络结构, 设计特征演示, 并用经验来评估这两类在线匹配问题: Edge- Weighted 在线双向匹配和在线子模块双向匹配。 我们显示,大多数学习方法比四个合成和真实世界数据集的经典基线算法表现得始终好。 平均而言, 我们提议的模型在各种合成和真实世界数据集上提高了3-10%的匹配质量。 我们的代码可以在https://github.com/lyeskhalil/CORL上公开查阅。