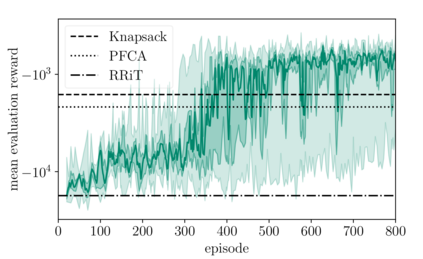
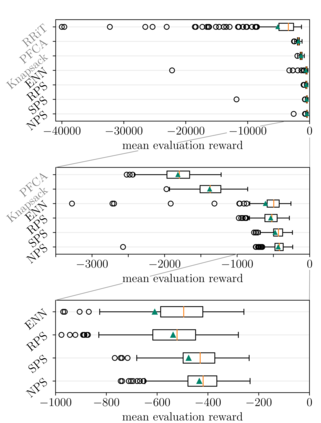
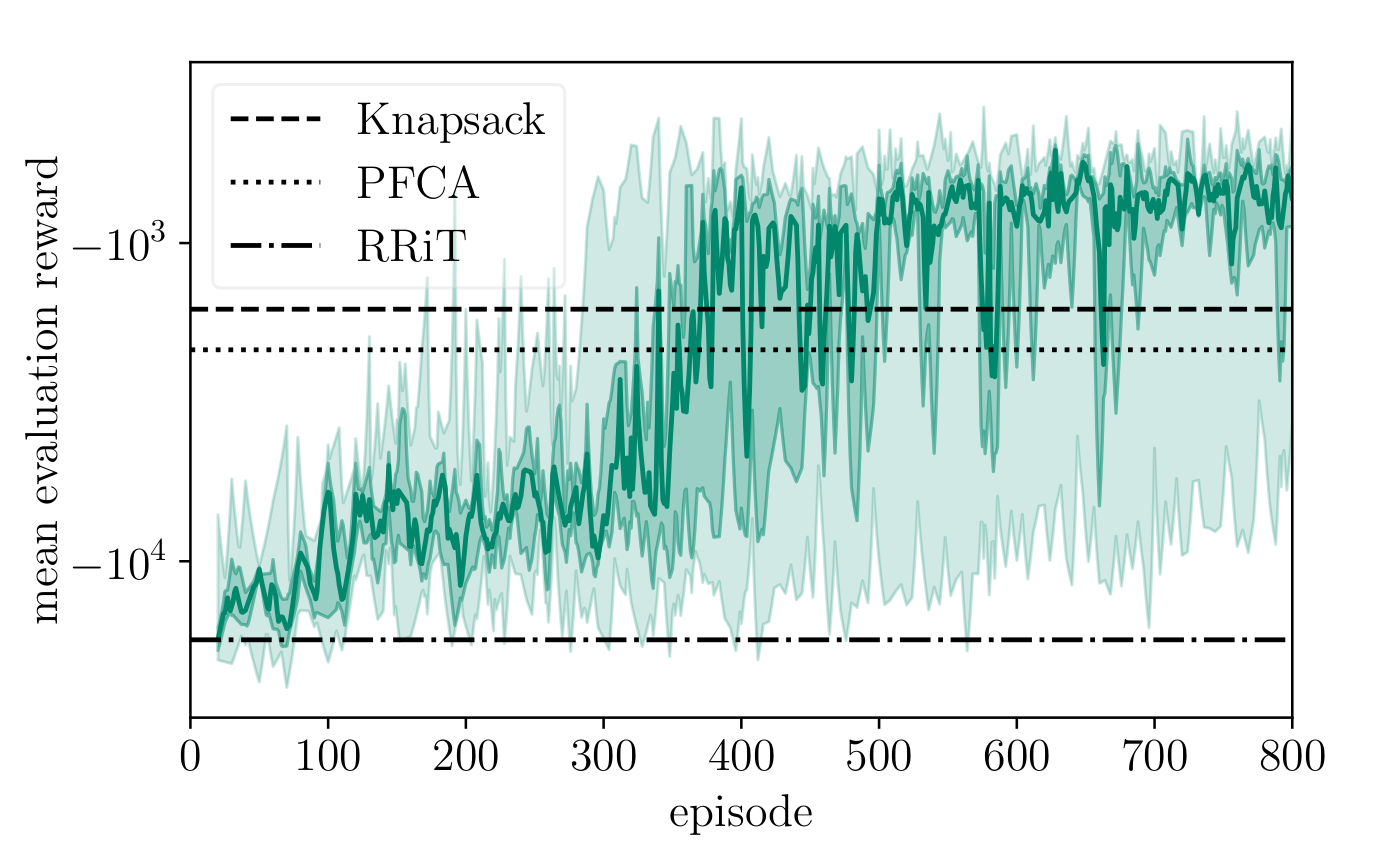
As the number of user equipments (UEs) with various data rate and latency requirements increases in wireless networks, the resource allocation problem for orthogonal frequency-division multiple access (OFDMA) becomes challenging. In particular, varying requirements lead to a non-convex optimization problem when maximizing the systems data rate while preserving fairness between UEs. In this paper, we solve the non-convex optimization problem using deep reinforcement learning (DRL). We outline, train and evaluate a DRL agent, which performs the task of media access control scheduling for a downlink OFDMA scenario. To kickstart training of our agent, we introduce mimicking learning. For improvement of scheduling performance, full buffer state information at the base station (e.g. packet age, packet size) is taken into account. Techniques like input feature compression, packet shuffling and age capping further improve the performance of the agent. We train and evaluate our agents using Nokia's wireless suite and evaluate against different benchmark agents. We show that our agents clearly outperform the benchmark agents.
翻译:随着无线网络中各种数据率和延迟要求的用户设备数量增加,正方频率多访问(OFDMA)的资源分配问题变得具有挑战性,特别是,不同要求导致在最大使用系统数据率时出现非conex优化问题,同时保持UES之间的公平性。在本文件中,我们通过深层强化学习(DRL)解决非convex优化问题。我们计划、训练和评价一个DRL代理,该代理为DMA的下链接执行媒体访问控制时间表安排任务。为了启动对我们的代理的培训,我们引入模拟学习。为了改进时间安排性能,将基础站的全部缓冲状态信息(例如包龄、包体大小)考虑在内。像输入特性压缩、包体打和年龄上限等技术进一步提高了代理的性能。我们用Nokia的无线套装来培训和评估我们的代理,并对照不同的基准代理进行评估。我们显示,我们的代理明显超越基准代理。