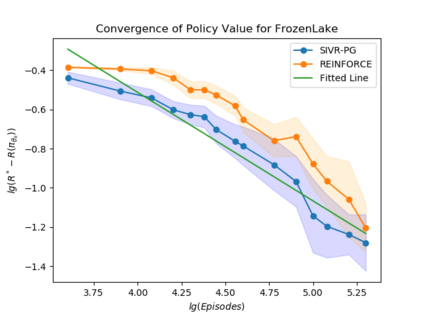
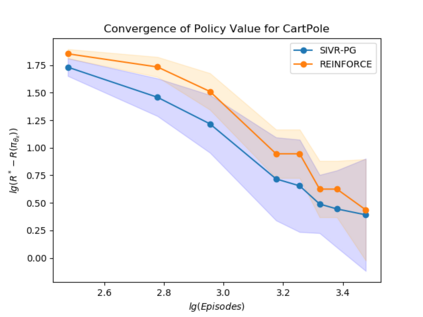
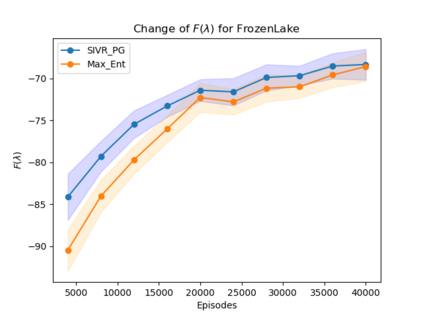
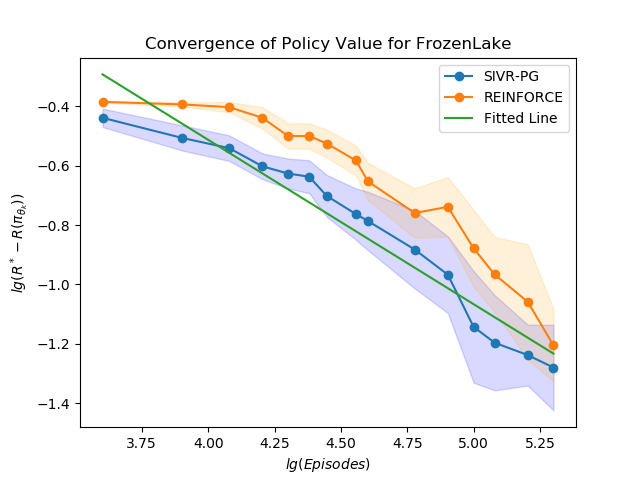
Policy gradient gives rise to a rich class of reinforcement learning (RL) methods, for example the REINFORCE. Yet the best known sample complexity result for such methods to find an $\epsilon$-optimal policy is $\mathcal{O}(\epsilon^{-3})$, which is suboptimal. In this paper, we study the fundamental convergence properties and sample efficiency of first-order policy optimization method. We focus on a generalized variant of policy gradient method, which is able to maximize not only a cumulative sum of rewards but also a general utility function over a policy's long-term visiting distribution. By exploiting the problem's hidden convex nature and leveraging techniques from composition optimization, we propose a Stochastic Incremental Variance-Reduced Policy Gradient (SIVR-PG) approach that improves a sequence of policies to provably converge to the global optimal solution and finds an $\epsilon$-optimal policy using $\tilde{\mathcal{O}}(\epsilon^{-2})$ samples.
翻译:政策梯度产生了一大批强化学习方法(RL),例如REINFORCE。然而,最已知的这种方法寻找$$\epsilon$-最佳政策的抽样复杂结果是美元(mathcal{O}(\\epsilon ⁇ --3})美元,这是不理想的。在本文中,我们研究了一级政策优化方法的基本趋同特性和抽样效率。我们侧重于政策梯度方法的普遍变异,它不仅能够使奖励的累积总和最大化,而且能够对政策的长期访问分布产生一般的效用功能。我们通过利用问题隐藏的convex性质和从构成优化中利用技术,提出了一种SIVR-PG(SIVR-PG)方法,改进了政策序列,以便与全球最佳解决方案相趋同,并找到一个使用 $\epsilon$-tmal suple 政策,使用 $\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\