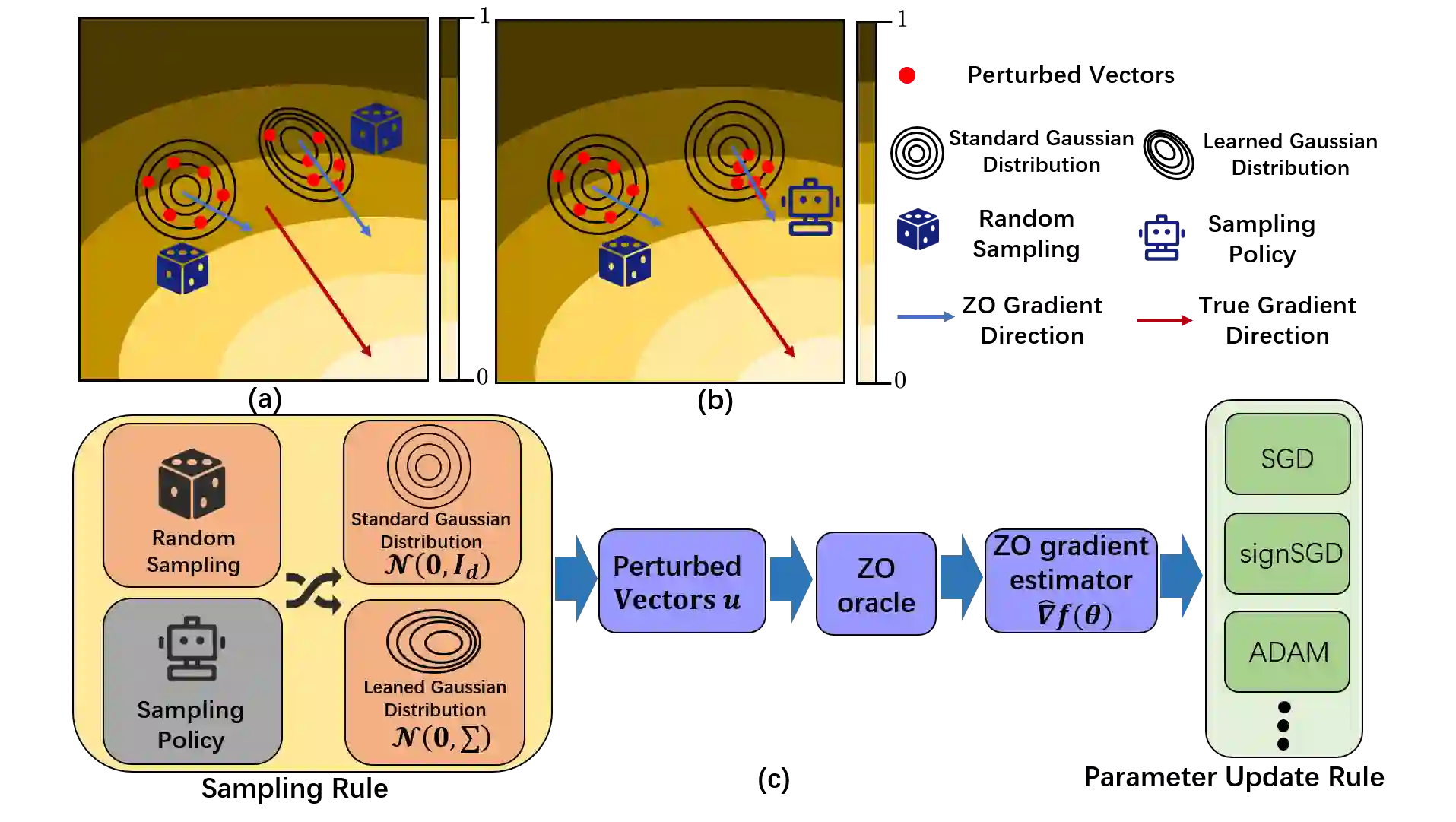
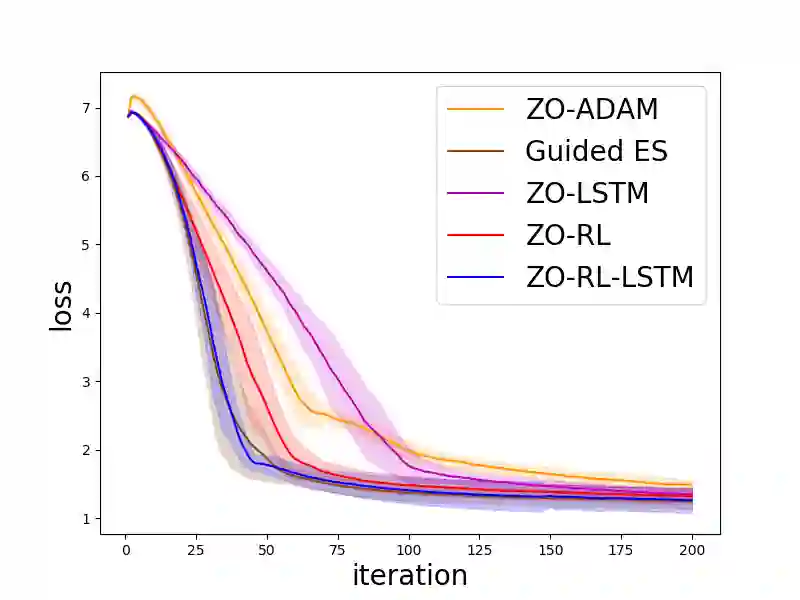
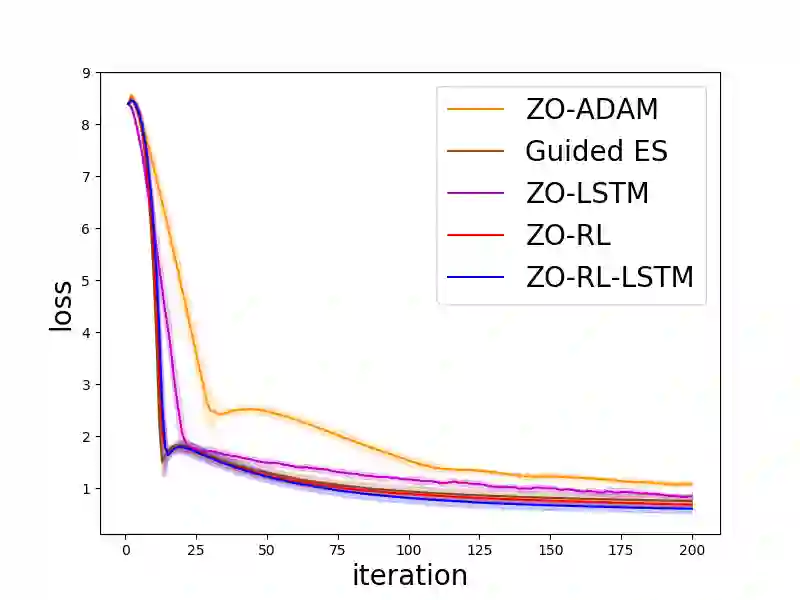
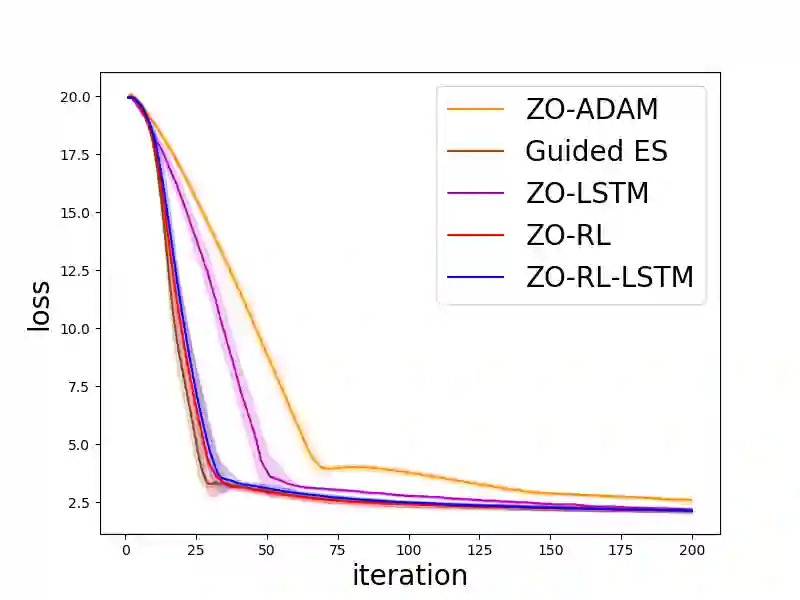
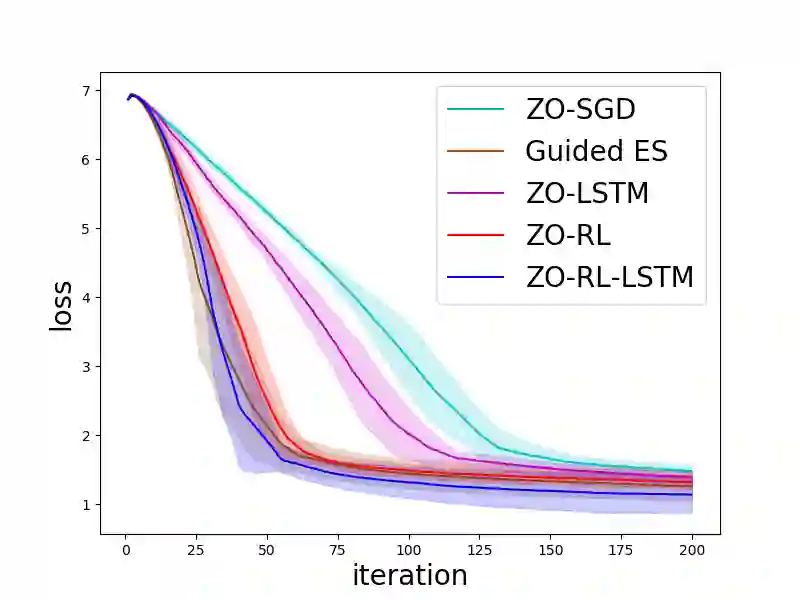
Zeroth-order (ZO, also known as derivative-free) methods, which estimate the gradient only by two function evaluations, have attracted much attention recently because of its broad applications in machine learning community. The two function evaluations are normally generated with random perturbations from standard Gaussian distribution. To speed up ZO methods, many methods, such as variance reduced stochastic ZO gradients and learning an adaptive Gaussian distribution, have recently been proposed to reduce the variances of ZO gradients. However, it is still an open problem whether there is a space to further improve the convergence of ZO methods. To explore this problem, in this paper, we propose a new reinforcement learning based ZO algorithm (ZO-RL) with learning the sampling policy for generating the perturbations in ZO optimization instead of using random sampling. To find the optimal policy, an actor-critic RL algorithm called deep deterministic policy gradient (DDPG) with two neural network function approximators is adopted. The learned sampling policy guides the perturbed points in the parameter space to estimate a more accurate ZO gradient. To the best of our knowledge, our ZO-RL is the first algorithm to learn the sampling policy using reinforcement learning for ZO optimization which is parallel to the existing methods. Especially, our ZO-RL can be combined with existing ZO algorithms that could further accelerate the algorithms. Experimental results for different ZO optimization problems show that our ZO-RL algorithm can effectively reduce the variances of ZO gradient by learning a sampling policy, and converge faster than existing ZO algorithms in different scenarios.
翻译:零顺序( ZO, 也称为无衍生物) 方法, 仅用两个函数评价来估计梯度, 最近因其在机器学习界的广泛应用而引起人们的注意。 两个函数评价通常是从标准的 Gaussian 分布中随机扰动生成的。 为了加速 ZO 方法, 最近提出了许多方法, 如差异减少的随机偏差 ZO 梯度和学习适应性的 Gausian 分布, 以降低 ZO 梯度的差异。 然而, 是否还有空间进一步改进 ZO 方法的趋同性, 仍然是一个开放的问题。 为了探索这一问题, 我们提议一个新的基于 ZO 算法( ZO- R- RLLL) 的强化学习策略。 为了找到最佳的政策, 一个叫“ 动作- 刺激性 RLLL 算法”, 称为“ 深度确定性政策梯度梯度( DDPG ) ”, 由两个神经网络函数进一步匹配 。 学习的取样政策政策会为参数 Z 的更深点提供指导 。,, 将 UR 值 Z 的 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值, 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值 值