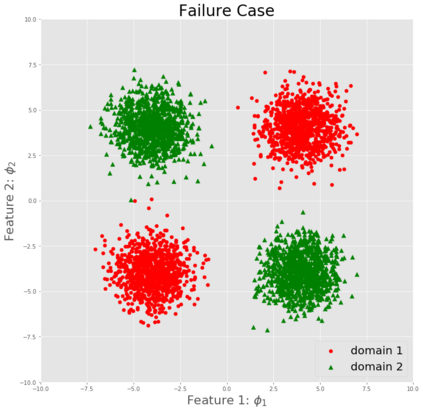
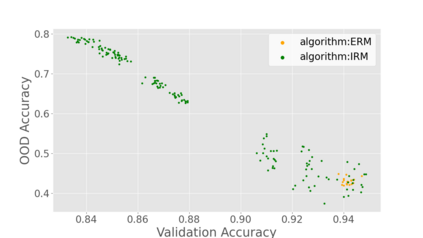
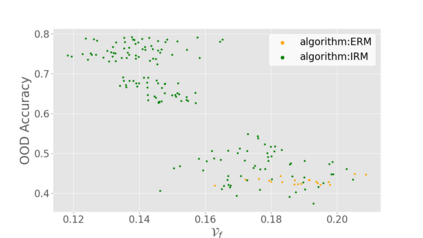
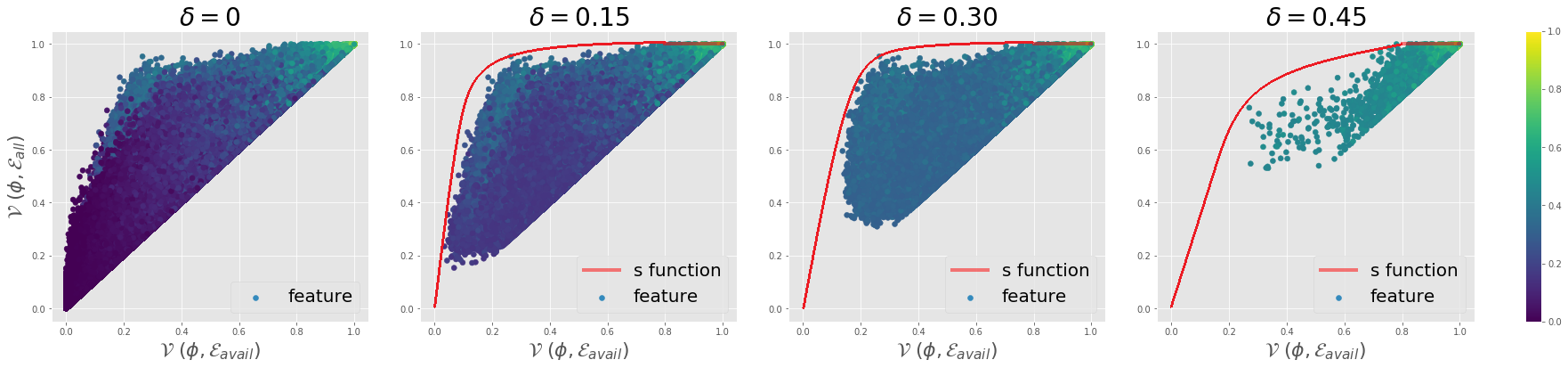
Generalization to out-of-distribution (OOD) data, or domain generalization, is one of the central problems in modern machine learning. Recently, there is a surge of attempts to propose algorithms for OOD that mainly build upon the idea of extracting invariant features. Although intuitively reasonable, theoretical understanding of what kind of invariance can guarantee OOD generalization is still limited, and generalization to arbitrary out-of-distribution is clearly impossible. In this work, we take the first step towards rigorous and quantitative definitions of 1) what is OOD; and 2) what does it mean by saying an OOD problem is learnable. We also introduce a new concept of expansion function, which characterizes to what extent the variance is amplified in the test domains over the training domains, and therefore give a quantitative meaning of invariant features. Based on these, we prove OOD generalization error bounds. It turns out that OOD generalization largely depends on the expansion function. As recently pointed out by Gulrajani and Lopez-Paz (2020), any OOD learning algorithm without a model selection module is incomplete. Our theory naturally induces a model selection criterion. Extensive experiments on benchmark OOD datasets demonstrate that our model selection criterion has a significant advantage over baselines.
翻译:在现代机器学习中,普遍分配(OOOD)数据或领域概括化是一个中心问题。最近,有人试图提出OOOD的算法,这些算法主要以提取变化特性的理念为基础。虽然直觉上对何种差异可以保证OOOD的概括化的理论理解仍然有限,而笼统化任意分配(OOOD)数据显然是不可能的。在这项工作中,我们迈出第一步,对1(OOOD)的严格和定量定义采取严格和定量的定义;以及2)说OOOD问题是可以学习的,这意味着什么。我们还引入了扩展功能的新概念,它说明差异在测试域在培训域上放大的程度,从而给变量的量化含义。基于这些,我们证明OOOD一般化错误的界限。结果显示,OOOOD的概括化一般化主要取决于扩展功能。最近Gulrajani和Lop-Paz(2020年)指出,任何没有模型选择模块的OOOD学习算法的算法都是不完整的。我们的理论自然地诱导出了一个基准选择标准。