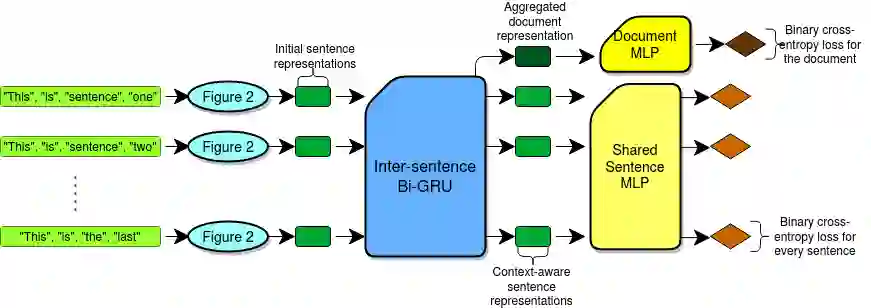
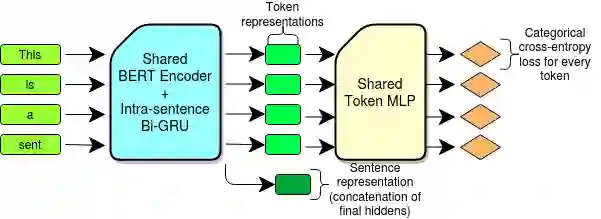
Annotating text data for event information extraction systems is hard, expensive, and error-prone. We investigate the feasibility of integrating coarse-grained data (document or sentence labels), which is far more feasible to obtain, instead of annotating more documents. We utilize a multi-task model with two auxiliary tasks, document and sentence binary classification, in addition to the main task of token classification. We perform a series of experiments with varying data regimes for the aforementioned integration. Results show that while introducing extra coarse-grained data offers greater improvement and robustness, a gain is still possible with only the addition of negative documents that have no information on any event.
翻译:为事件信息提取系统提供说明性文本数据非常困难、昂贵和容易出错。我们调查将粗粗数据(文件或句号标签)整合的可行性,这种整合比说明性文件更可行,而不是更多文件。我们除了象征性分类的主要任务外,还使用一个多任务模式,包括两个辅助任务,即文档和句子二进制分类。我们为上述整合进行了一系列不同的数据制度实验。结果显示,虽然引入额外粗粗粗重数据可以提供更大的改进和稳健性,但只要增加没有任何事件信息的负面文件,仍有可能获得收益。