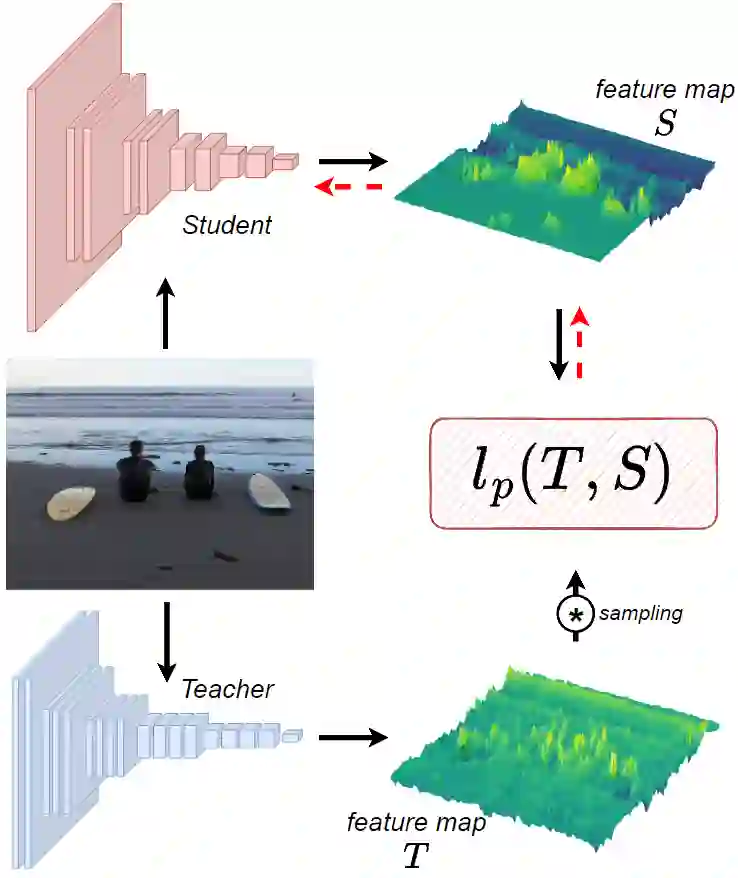
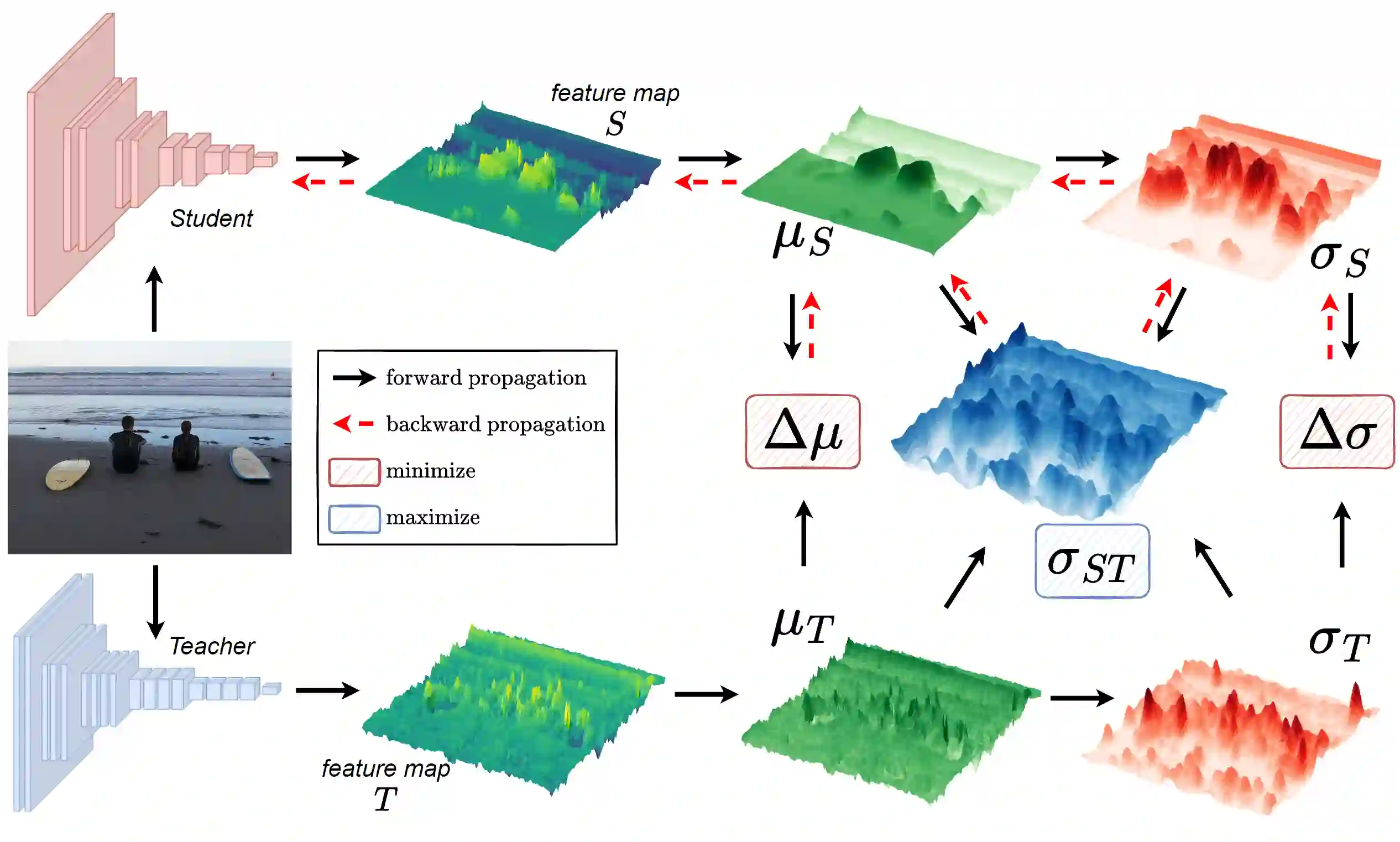
Knowledge Distillation (KD) is a well-known training paradigm in deep neural networks where knowledge acquired by a large teacher model is transferred to a small student. KD has proven to be an effective technique to significantly improve the student's performance for various tasks including object detection. As such, KD techniques mostly rely on guidance at the intermediate feature level, which is typically implemented by minimizing an lp-norm distance between teacher and student activations during training. In this paper, we propose a replacement for the pixel-wise independent lp-norm based on the structural similarity (SSIM). By taking into account additional contrast and structural cues, feature importance, correlation and spatial dependence in the feature space are considered in the loss formulation. Extensive experiments on MSCOCO demonstrate the effectiveness of our method across different training schemes and architectures. Our method adds only little computational overhead, is straightforward to implement and at the same time it significantly outperforms the standard lp-norms. Moreover, more complex state-of-the-art KD methods using attention-based sampling mechanisms are outperformed, including a +3.5 AP gain using a Faster R-CNN R-50 compared to a vanilla model.
翻译:知识蒸馏(KD)是深神经网络中一个众所周知的培训范例,在深神经网络中,通过大型教师模式获得的知识被转让给一个小学生。KD已证明是显著提高学生执行包括物体探测在内的各种任务绩效的有效技术。因此,KD技术主要依靠中等特征水平的指导,通常通过在培训期间尽量减少师生之间的低温距离来实施。在本文中,我们提议根据结构相似性(SSIM)来取代高视像素独立的低温。此外,在设计损失时,考虑到更多的对比和结构提示、特征重要性、在地貌空间的相互关系和空间依赖性。关于MSCO的广泛实验表明我们的方法在不同培训计划和结构中的有效性。我们的方法只增加少量计算间接费用,容易实施,同时大大超过标准的 lp-norms。此外,使用关注基取样机制的更复杂的高水平KD方法已经超越了模型,包括利用快速R-N的R-A+3.5获得。