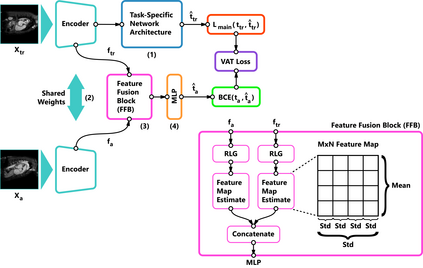
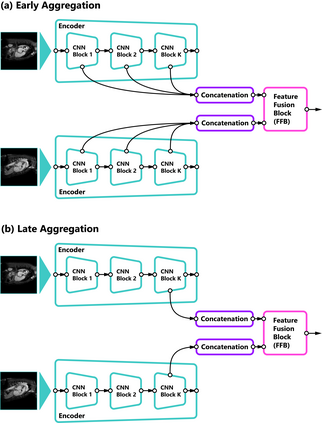
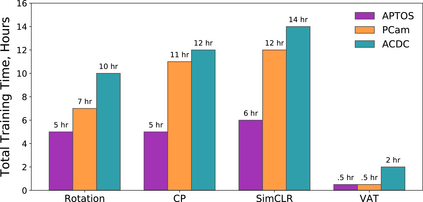
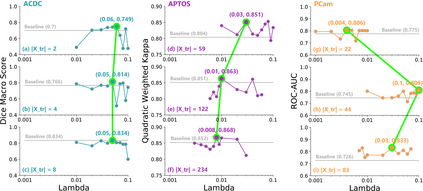
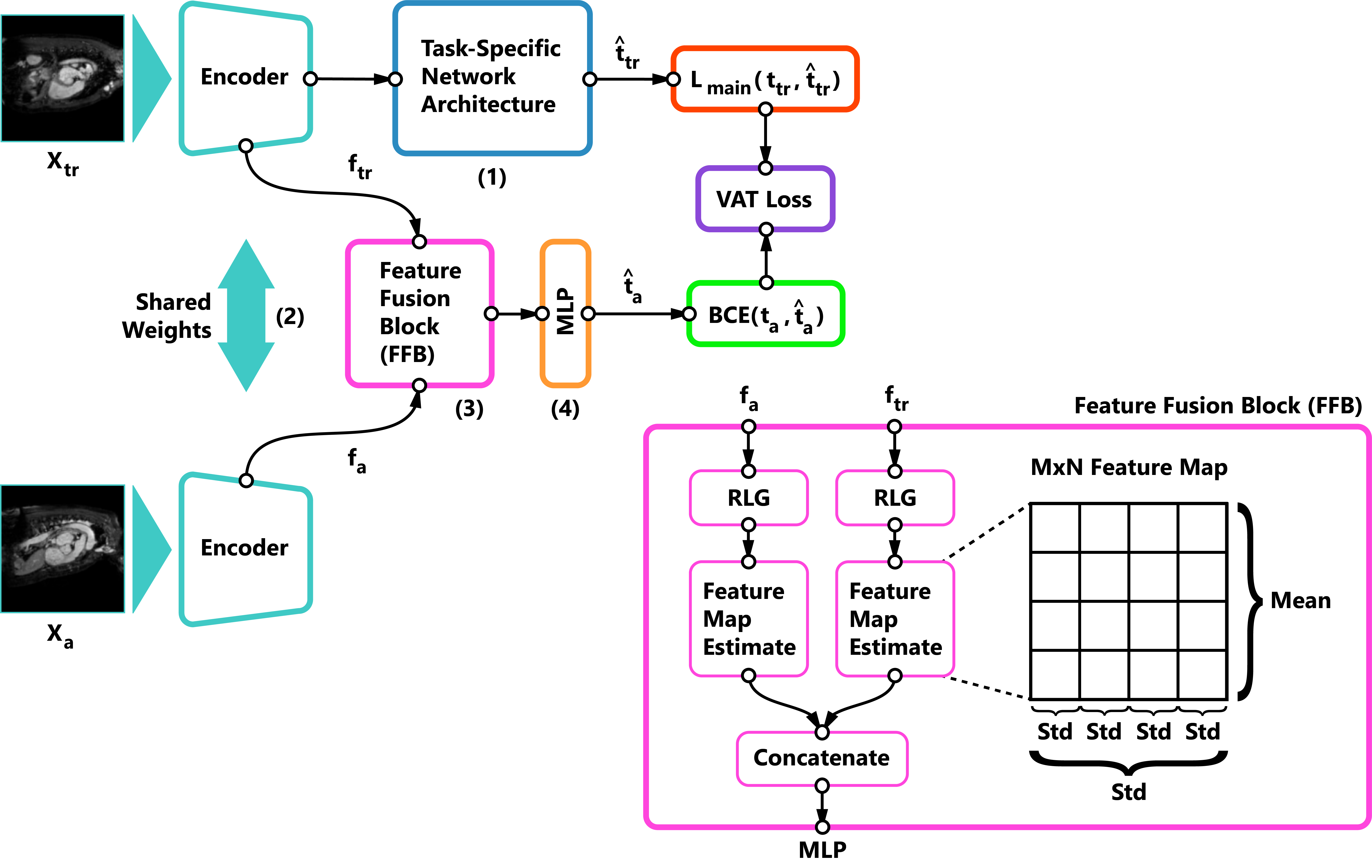
Self-supervised learning methods for computer vision have demonstrated the effectiveness of pre-training feature representations, resulting in well-generalizing Deep Neural Networks, even if the annotated data are limited. However, representation learning techniques require a significant amount of time for model training, with most of it time spent on precise hyper-parameter optimization and selection of augmentation techniques. We hypothesized that if the annotated dataset has enough morphological diversity to capture the general population's as is common in medical imaging, for example, due to conserved similarities of tissue mythologies, the variance error of the trained model is the prevalent component of the Bias-Variance Trade-off. We propose the Variance Aware Training (VAT) method that exploits this property by introducing the variance error into the model loss function, i.e., enabling minimizing the variance explicitly. Additionally, we provide the theoretical formulation and proof of the proposed method to aid in interpreting the approach. Our method requires selecting only one hyper-parameter and was able to match or improve the state-of-the-art performance of self-supervised methods while achieving an order of magnitude reduction in the GPU training time. We validated VAT on three medical imaging datasets from diverse domains and various learning objectives. These included a Magnetic Resonance Imaging (MRI) dataset for the heart semantic segmentation (MICCAI 2017 ACDC challenge), fundus photography dataset for ordinary regression of diabetic retinopathy progression (Kaggle 2019 APTOS Blindness Detection challenge), and classification of histopathologic scans of lymph node sections (PatchCamelyon dataset).
翻译:计算机视觉的自我监督学习方法显示了培训前的特征表现的有效性,因此,即使附加说明的数据有限,深神经网络也能够广泛推广。然而,代表性学习技术需要大量时间进行模型培训,大部分时间花在精确超光度优化和增强技术的选择上。我们假设,如果附加说明的数据集具有足够的形态多样性,可以捕捉普通人群,例如在医学成像中常见的形态多样性,例如,由于保存了组织上的血浆相似性,受过训练的模型的偏差是普通的“Bias-Variance 交易”的常见组成部分。我们建议采用“差异意识培训”方法,将差异错误引入模型损失功能,从而利用这一特性,即明确缩小差异。此外,我们提供了拟议方法的理论设计和证明,以帮助解释这一方法。我们的方法仅需要选择一个超常识度数据模型,并且能够匹配或改进自我监督的血压分析方法的状态性能。我们提出了“OVAAT ” 数据序列校验数据系统,同时学习了“GPOA” 数据结构的大小校正。