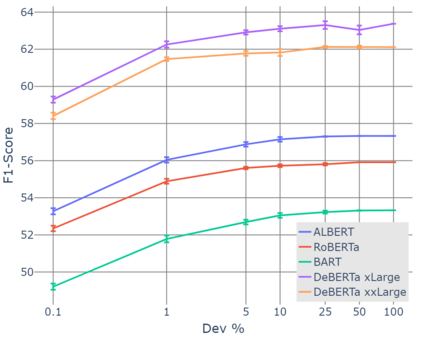
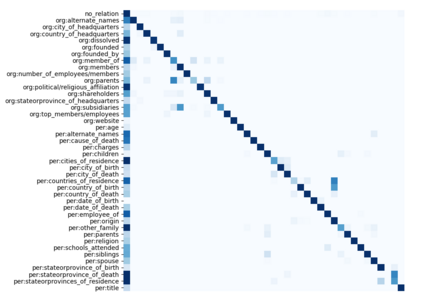
Relation extraction systems require large amounts of labeled examples which are costly to annotate. In this work we reformulate relation extraction as an entailment task, with simple, hand-made, verbalizations of relations produced in less than 15 min per relation. The system relies on a pretrained textual entailment engine which is run as-is (no training examples, zero-shot) or further fine-tuned on labeled examples (few-shot or fully trained). In our experiments on TACRED we attain 63% F1 zero-shot, 69% with 16 examples per relation (17% points better than the best supervised system on the same conditions), and only 4 points short to the state-of-the-art (which uses 20 times more training data). We also show that the performance can be improved significantly with larger entailment models, up to 12 points in zero-shot, allowing to report the best results to date on TACRED when fully trained. The analysis shows that our few-shot systems are specially effective when discriminating between relations, and that the performance difference in low data regimes comes mainly from identifying no-relation cases.
翻译:在这项工作中,我们重新将关系提取作为必然任务,以简单、手工和口头的方式对每份关系进行15分钟以下的描述。这个系统依靠的是预先训练的文本生成引擎,该引擎按原样运行(无培训实例,零发)或进一步微调(few-shot或经过充分培训的)标签示例。在TACRED实验中,我们达到63% F1零发,69%,每份样本16个(比同一条件下的最佳监督系统高17%),只有4个点短于最新数据(该设备使用的培训数据增加了20倍 ) 。 我们还表明,如果采用较大的要求模型,其性能可以大大改进,最多为零发点,从而能够在充分培训时在TACRED上报告迄今为止的最佳结果。分析表明,我们微小的系统在区分关系时特别有效,低数据系统中的性能差异主要来自确定无关系案例。