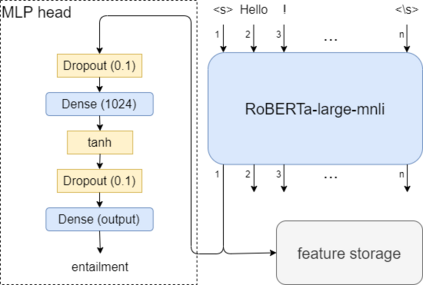
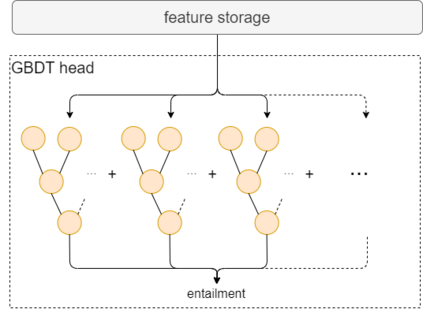
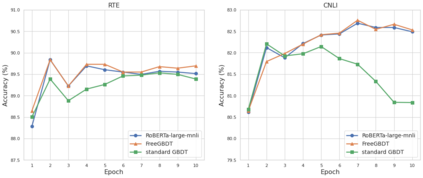
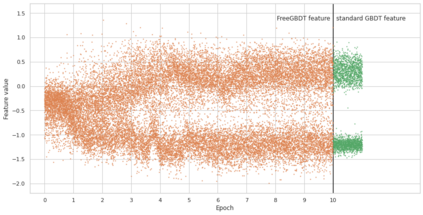
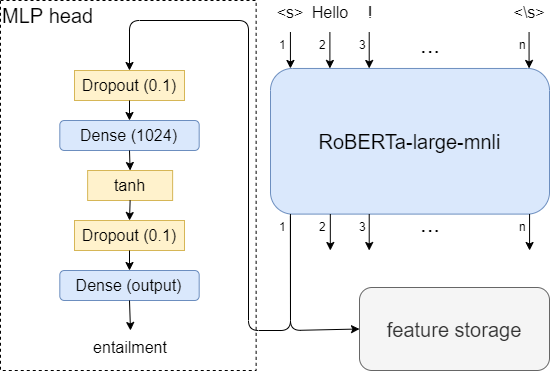
Transfer learning has become the dominant paradigm for many natural language processing tasks. In addition to models being pretrained on large datasets, they can be further trained on intermediate (supervised) tasks that are similar to the target task. For small Natural Language Inference (NLI) datasets, language modelling is typically followed by pretraining on a large (labelled) NLI dataset before fine-tuning with each NLI subtask. In this work, we explore Gradient Boosted Decision Trees (GBDTs) as an alternative to the commonly used Multi-Layer Perceptron (MLP) classification head. GBDTs have desirable properties such as good performance on dense, numerical features and are effective where the ratio of the number of samples w.r.t the number of features is low. We then introduce FreeGBDT, a method of fitting a GBDT head on the features computed during fine-tuning to increase performance without additional computation by the neural network. We demonstrate the effectiveness of our method on several NLI datasets using a strong baseline model (RoBERTa-large with MNLI pretraining). The FreeGBDT shows a consistent improvement over the MLP classification head.
翻译:许多自然语言处理任务的主要模式是转移学习。除了在大型数据集上预先培训模型外,还可以在与目标任务相似的中间(监督)任务方面对其进行进一步培训。对于小型自然语言推断数据集,语言建模后通常先在大型(标签的)国家语言推断数据集上进行预先培训,然后与每个国家语言分类的子任务单位进行微调。在这项工作中,我们探索了渐进式推导决定树(GBDTs),作为常用的多层 Percepron(MLP)分类头的替代物。GBDTs具有与目标任务相似的良好性能,如密度、数字特征和在样本数量比例低的情况下有效。然后我们引入了自由GBDT,这是在微调期间将GBDT头部安装在提高性能而不由神经网络进行额外计算的方法上的一种方法。我们用强大的基线模型(ROBERTA和MLII头列)展示了我们关于若干国家语言分类方法的有效性。FreeGBDDG的改进是连续的。