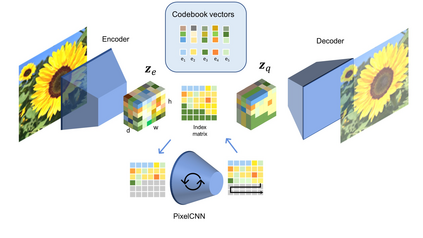
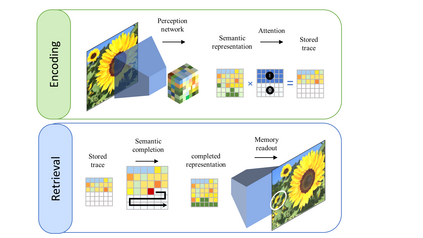
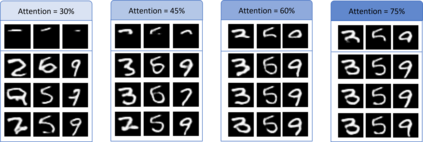
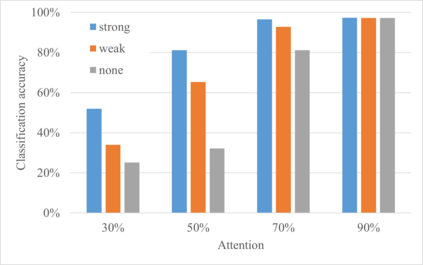
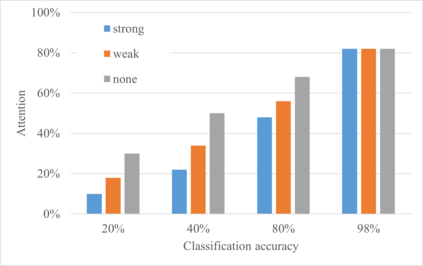
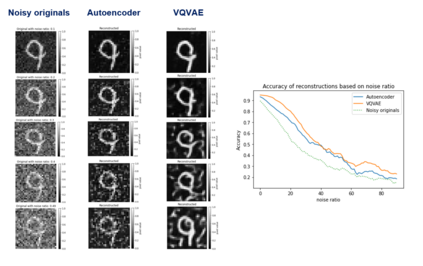
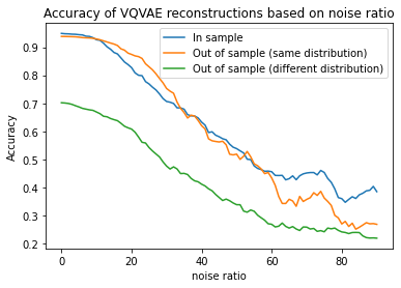
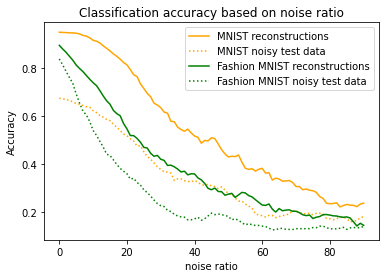
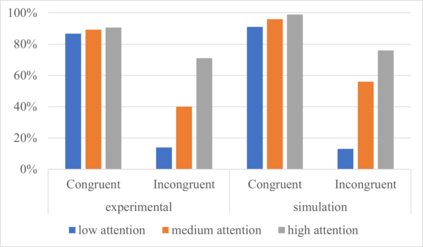
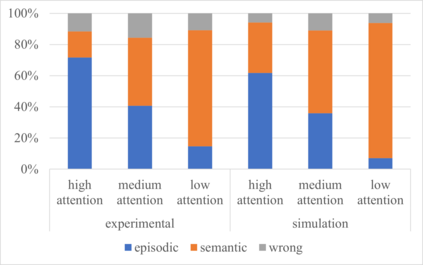
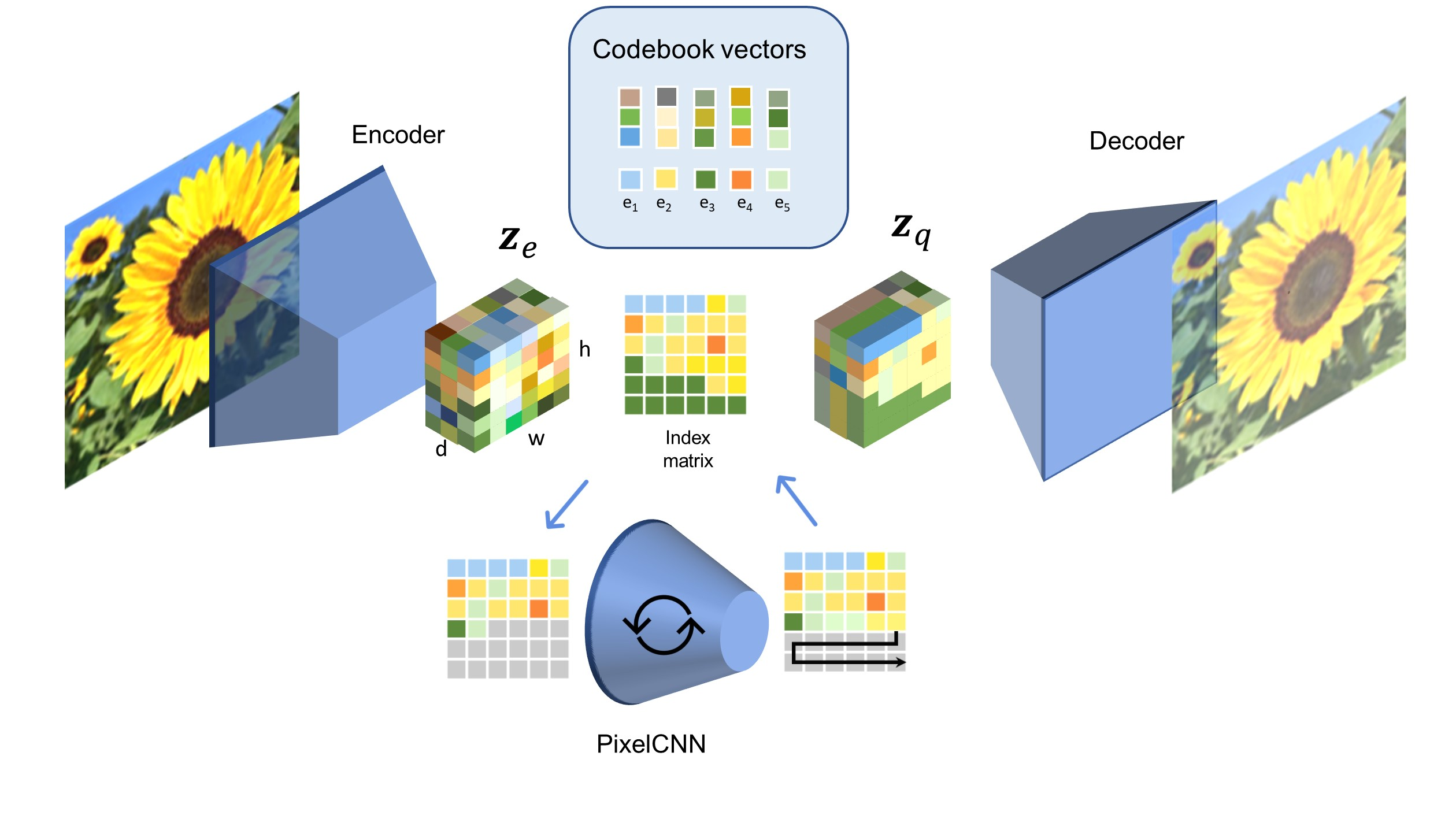
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
翻译:许多不同研究都表明,内存是遗传过程,但大多数计算模型都采用了存储视图。在这项工作中,我们建议了一个基因内存的计算模型。它基于一个中心假设,即hippocampus 存储并检索某一插曲的某些部分作为记忆跟踪,这必然是不完整的。回顾,新皮层根据一般语义信息合理地填充了缺失的信息,我们称之为语义补全。随着我们使用由不同背景代表背景放大的数字图像(MNIST)的时段,我们的模型以VQ-VAE为基础,以索引矩阵的形式生成压缩的隐性表达方式,该模型仍然有一些空间解析。我们假设,注意选择了索引矩阵的某些部分,而另一些则被丢弃,这代表了该插曲的线索,并存储了记忆跟踪。回顾,缺失部分被填充成一个PixelCNN, 建模完成语义补全,而完成的索引矩阵通常可以通过VQ-VAE型模型解析成完整图像。模型的内存层的内存的内存也能够完全的内存的内存的内存到内存的内存,因此,该模型可以将内存的内存的内存的内存的内存到内存的内存的内存到内存到内存的内存的内存的内存的内存到内存到内存到内存的内存的内存的内存的内存的内存到内存的内存的内存的内存到内存的内存的内存的内存到内存到内存到内存到内存的内存的内存的内存层。