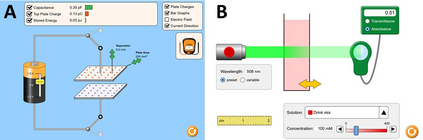
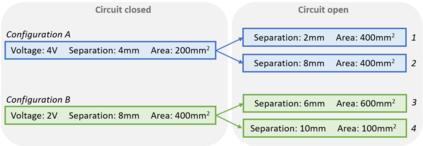
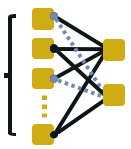
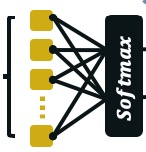
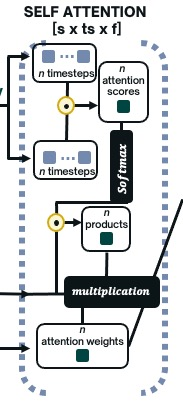
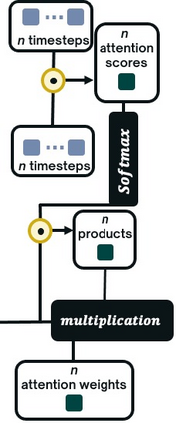
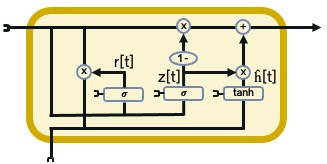
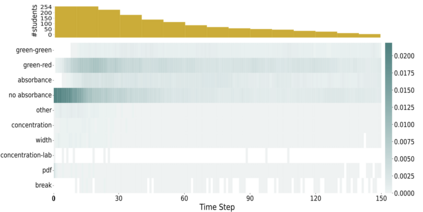
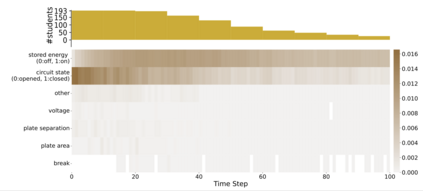
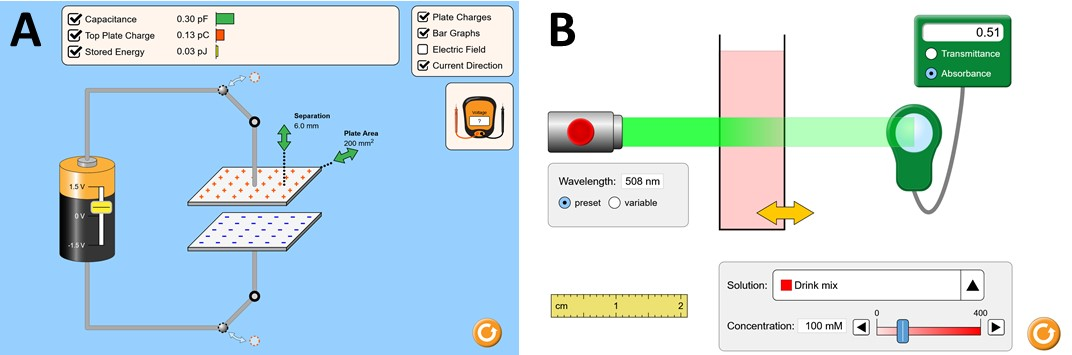
Interactive simulations allow students to discover the underlying principles of a scientific phenomenon through their own exploration. Unfortunately, students often struggle to learn effectively in these environments. Classifying students' interaction data in the simulations based on their expected performance has the potential to enable adaptive guidance and consequently improve students' learning. Previous research in this field has mainly focused on a-posteriori analyses or investigations limited to one specific predictive model and simulation. In this paper, we investigate the quality and generalisability of models for an early prediction of conceptual understanding based on clickstream data of students across interactive simulations. We first measure the students' conceptual understanding through their in-task performance. Then, we suggest a novel type of features that, starting from clickstream data, encodes both the state of the simulation and the action performed by the student. We finally propose to feed these features into GRU-based models, with and without attention, for prediction. Experiments on two different simulations and with two different populations show that our proposed models outperform shallow learning baselines and better generalise to different learning environments and populations. The inclusion of attention into the model increases interpretability in terms of effective inquiry. The source code is available on Github (https://github.com/epfl-ml4ed/beerslaw-lab.git).
翻译:互动模拟使学生能够通过自己的探索发现科学现象的基本原理。 不幸的是,学生们常常在这些环境中努力地有效地学习。根据学生的预期性能对模拟中学生的相互作用数据进行分类,有可能促成适应性指导,从而改进学生的学习。这个领域的以往研究主要侧重于一种现象分析或调查,仅限于一个特定的预测模型和模拟。在本文中,我们调查基于学生在交互式模拟中点击流数据早期预测概念理解模型的质量和可概括性。我们首先通过学生在其中的性能测量学生的概念理解。然后,我们建议从点击流数据开始,将学生的模拟和行为情况编码为新颖的特征。我们最后提议将这些特征输入基于GRU的模型,有的和没有注意的,用于预测。对两种不同的模拟和两种不同的人口进行的实验表明,我们提议的模型超越了浅度学习基线,对不同的学习环境和人口作了更好的概括性。将注意力纳入模型中,从点击流数据开始,从而增加有效调查的可解释性。 源代码可以用于Girub/flibbs。