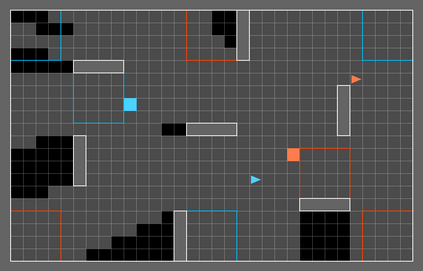
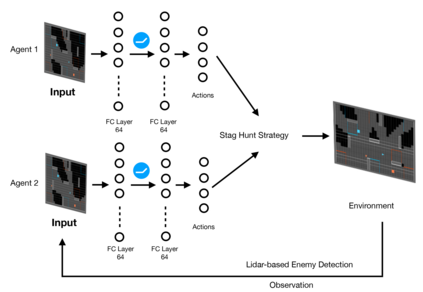
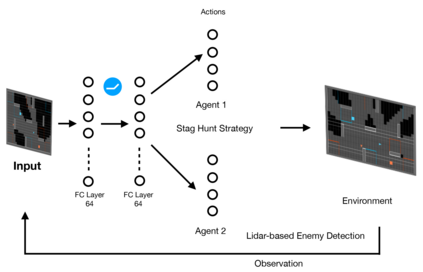
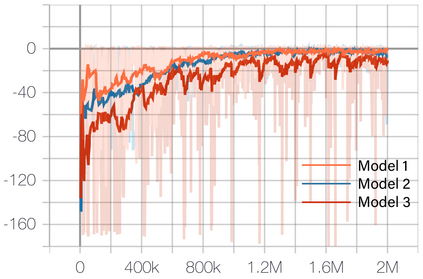
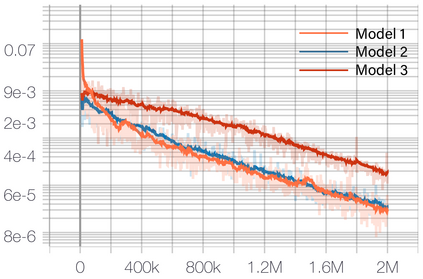
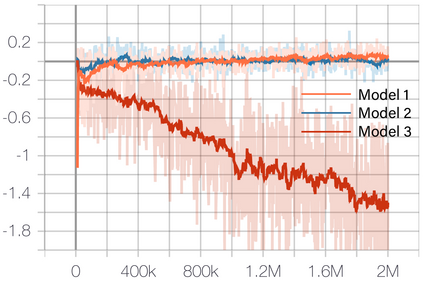
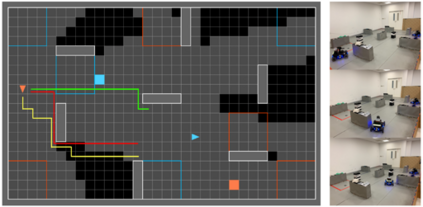
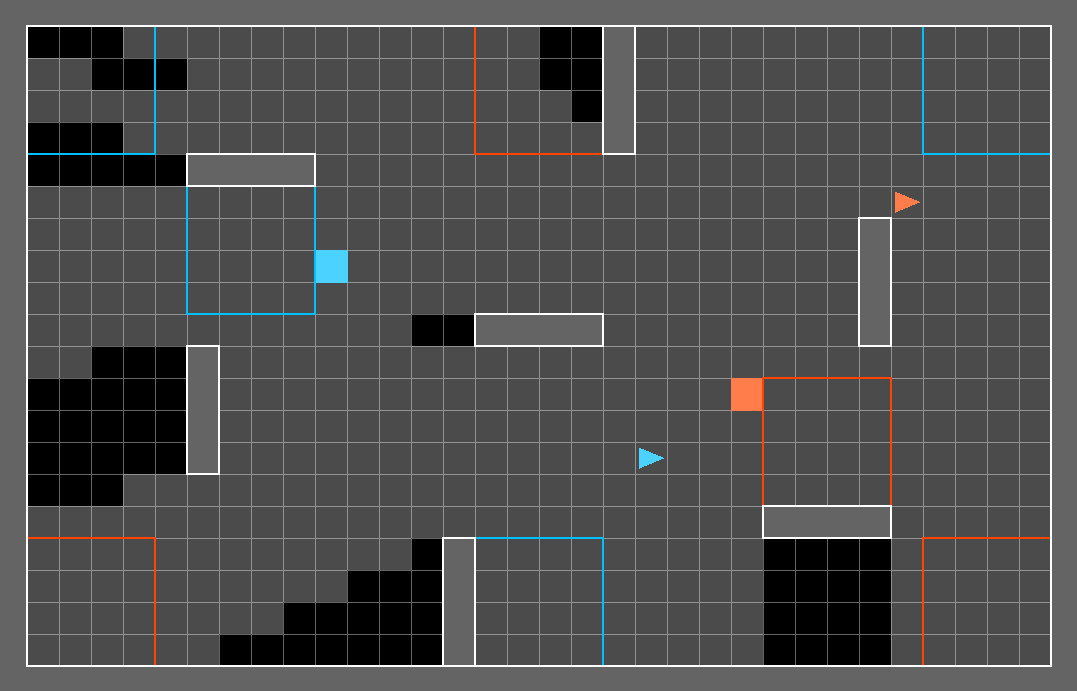
Deep Reinforcement Learning (DRL) has shown its promising capabilities to learn optimal policies directly from trial and error. However, learning can be hindered if the goal of the learning, defined by the reward function, is "not optimal". We demonstrate that by setting the goal/target of competition in a counter-intuitive but intelligent way, instead of heuristically trying solutions through many hours the DRL simulation can quickly converge into a winning strategy. The ICRA-DJI RoboMaster AI Challenge is a game of cooperation and competition between robots in a partially observable environment, quite similar to the Counter-Strike game. Unlike the traditional approach to games, where the reward is given at winning the match or hitting the enemy, our DRL algorithm rewards our robots when in a geometric-strategic advantage, which implicitly increases the winning chances. Furthermore, we use Deep Q Learning (DQL) to generate multi-agent paths for moving, which improves the cooperation between two robots by avoiding the collision. Finally, we implement a variant A* algorithm with the same implicit geometric goal as DQL and compare results. We conclude that a well-set goal can put in question the need for learning algorithms, with geometric-based searches outperforming DQL in many orders of magnitude.
翻译:深入强化学习(DRL)展示了直接从试验和错误中学习最佳政策的有希望的能力。然而,如果由奖励功能界定的学习目标“不是最佳”的话,学习就会受到阻碍。我们证明,通过以反直觉但明智的方式设定竞争目标/目标,而不是通过许多小时的超常尝试解决方案,DRL模拟可以很快地形成一个成功的策略。ICRA-DJI RoboMaster AI Challenge是一个在部分可观测环境中机器人之间合作和竞争的游戏,与反史崔克游戏非常相似。与传统的游戏方法不同的是,我们的DRL算法在赢得比赛或击败敌人时给予奖励,在几何战略优势的情况下奖励我们的机器人,这意味着增加获胜的机会。此外,我们利用深度Q学习(DQL)来创造多试样移动路径,通过避免碰撞来改善两个机器人之间的合作。最后,我们采用了一种与DQL相同的隐含几何目标的变式A*算法。我们的结论是,在深度搜索时,可以将许多测算结果与基于测程的QQQ。