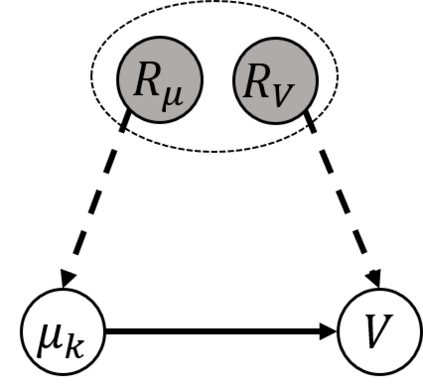
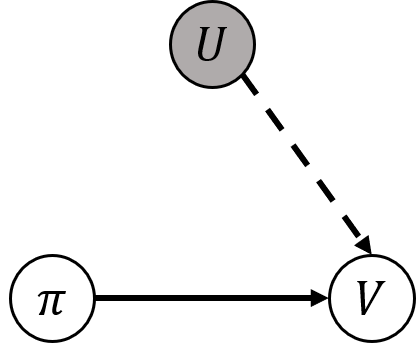
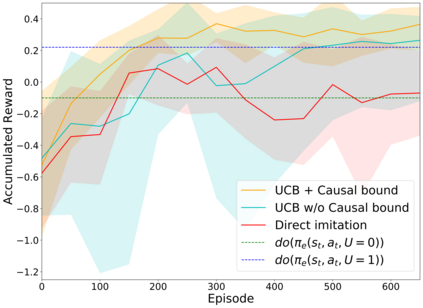
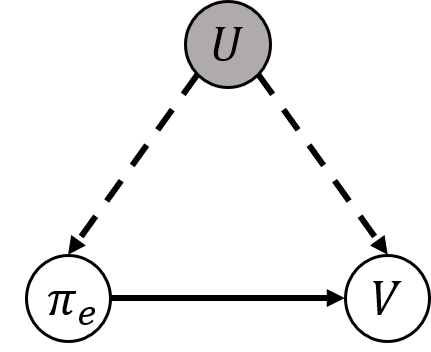
In this paper, we consider a transfer Reinforcement Learning (RL) problem in continuous state and action spaces, under unobserved contextual information. For example, the context can represent the mental view of the world that an expert agent has formed through past interactions with this world. We assume that this context is not accessible to a learner agent who can only observe the expert data. Then, our goal is to use the context-aware expert data to learn an optimal context-unaware policy for the learner using only a few new data samples. Such problems are typically solved using imitation learning that assumes that both the expert and learner agents have access to the same information. However, if the learner does not know the expert context, using the expert data alone will result in a biased learner policy and will require many new data samples to improve. To address this challenge, in this paper, we formulate the learning problem as a causal bound-constrained Multi-Armed-Bandit (MAB) problem. The arms of this MAB correspond to a set of basis policy functions that can be initialized in an unsupervised way using the expert data and represent the different expert behaviors affected by the unobserved context. On the other hand, the MAB constraints correspond to causal bounds on the accumulated rewards of these basis policy functions that we also compute from the expert data. The solution to this MAB allows the learner agent to select the best basis policy and improve it online. And the use of causal bounds reduces the exploration variance and, therefore, improves the learning rate. We provide numerical experiments on an autonomous driving example that show that our proposed transfer RL method improves the learner's policy faster compared to existing imitation learning methods and enjoys much lower variance during training.
翻译:在本文中,我们考虑的是连续状态和行动空间中的“强化学习”问题。在未观测到的背景信息下,我们考虑的是连续状态和行动空间中的“强化学习”问题。例如,背景可以代表专家代理人过去与世界互动形成的世界精神观点。我们假设,只有观察专家数据才能使学习者接触这一背景,而学习者只能观察专家数据。然后,我们的目标是利用环境认知的专家数据为学习者学习一种最佳的环境软件政策,只使用少量新的数据样本。这些问题通常通过模拟学习来加以解决,这种模拟学习者可以获取相同的信息。因此,如果学习者不了解专家背景,仅使用专家数据就会导致偏差学习政策,需要许多新的数据样本才能改进这一背景。为了应对这一挑战,我们在本文中将学习问题描述为因果约束性很强的多Armed-Bandit(MAB)问题。这个MAB的臂与一套基础政策功能相对应,这些功能可以以不受监督的方式初始化,利用专家数据和模型,因此,如果学习者不熟悉专家背景环境,那么,则会降低这种模拟政策中的学习速度,并且代表了不同方法在研究基础上受到影响。