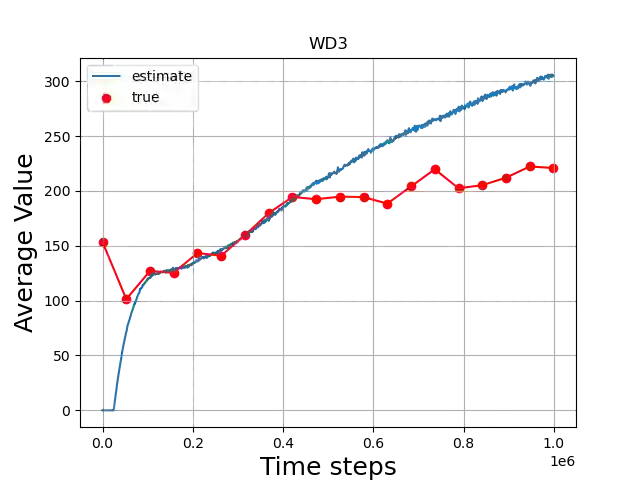
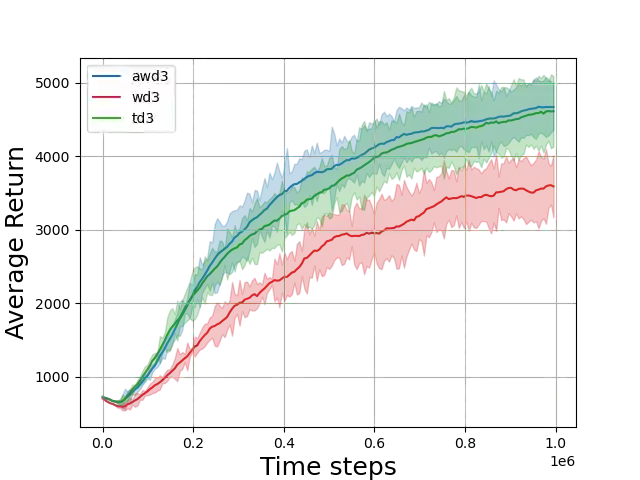
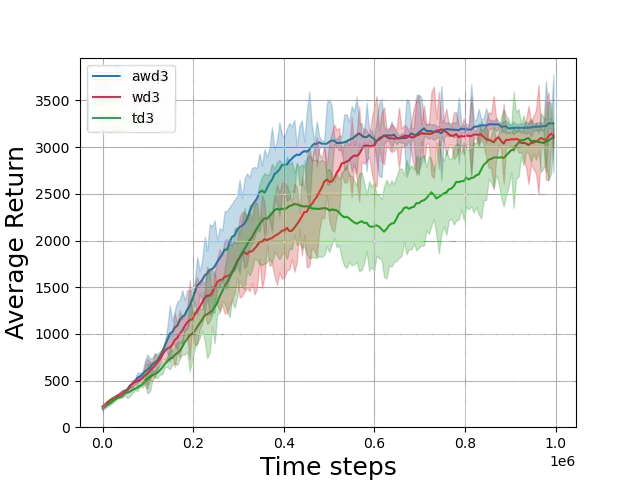
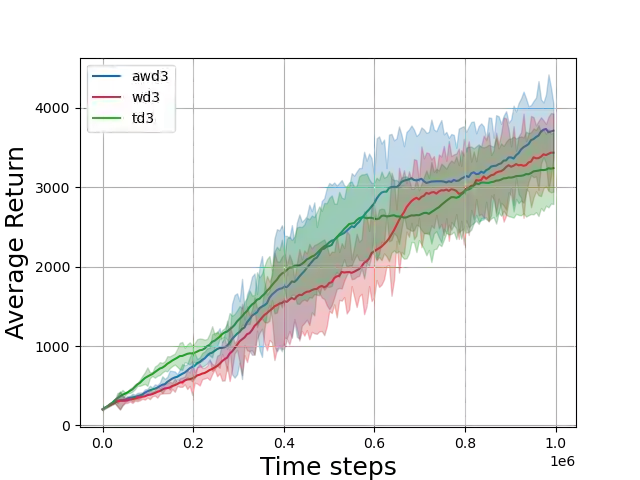
Value-based deep Reinforcement Learning (RL) algorithms suffer from the estimation bias primarily caused by function approximation and temporal difference (TD) learning. This problem induces faulty state-action value estimates and therefore harms the performance and robustness of the learning algorithms. Although several techniques were proposed to tackle, learning algorithms still suffer from this bias. Here, we introduce a technique that eliminates the estimation bias in off-policy continuous control algorithms using the experience replay mechanism. We adaptively learn the weighting hyper-parameter beta in the Weighted Twin Delayed Deep Deterministic Policy Gradient algorithm. Our method is named Adaptive-WD3 (AWD3). We show through continuous control environments of OpenAI gym that our algorithm matches or outperforms the state-of-the-art off-policy policy gradient learning algorithms.
翻译:基于价值的深强化学习算法受到主要由功能近似值和时间差异(TD)学习引起的估计偏差的偏差。 这个问题导致州- 行动价值估计有误, 从而损害学习算法的性能和稳健性。 虽然提出了几种方法要解决, 学习算法仍然受到这种偏差的影响 。 在这里, 我们引入一种技术, 利用经验重放机制消除非政策性连续控制算法的估计偏差 。 我们适应性地学习了“ 双重重重延迟的深层确定性政策梯度算法” 中的超参数贝。 我们的方法叫做适应- WD3 (AWD3)。 我们通过OpenAI 健身房的持续控制环境显示, 我们的算法匹配或优于最先进的离政策梯度学习算法。