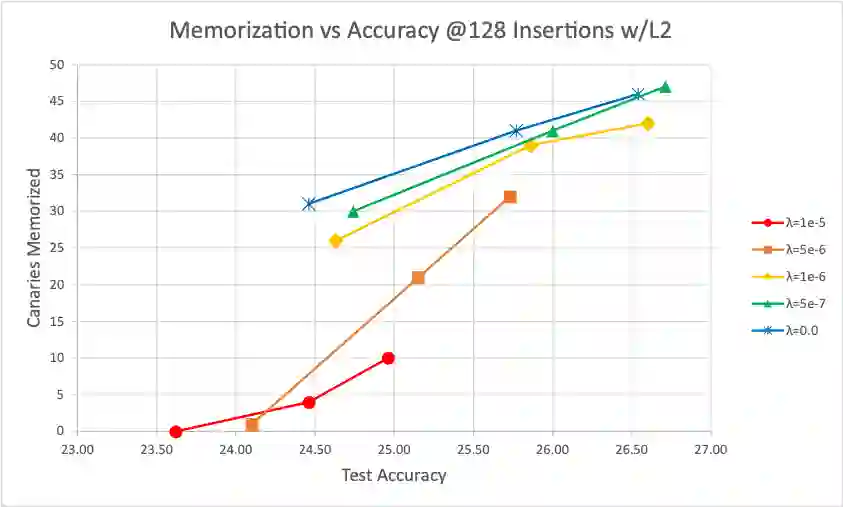
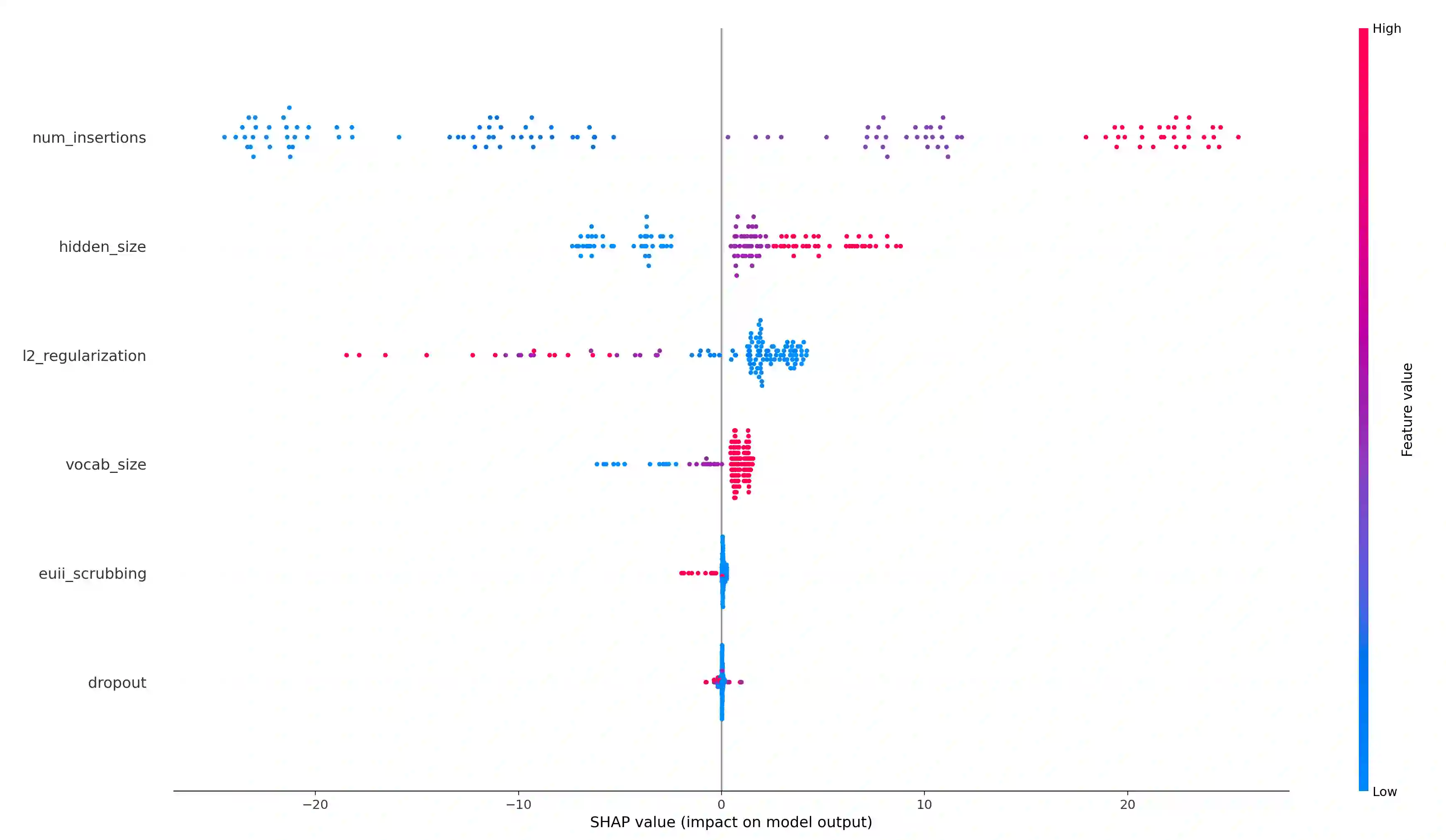
Language models are widely deployed to provide automatic text completion services in user products. However, recent research has revealed that language models (especially large ones) bear considerable risk of memorizing private training data, which is then vulnerable to leakage and extraction by adversaries. In this study, we test the efficacy of a range of privacy-preserving techniques to mitigate unintended memorization of sensitive user text, while varying other factors such as model size and adversarial conditions. We test both "heuristic" mitigations (those without formal privacy guarantees) and Differentially Private training, which provides provable levels of privacy at the cost of some model performance. Our experiments show that (with the exception of L2 regularization), heuristic mitigations are largely ineffective in preventing memorization in our test suite, possibly because they make too strong of assumptions about the characteristics that define "sensitive" or "private" text. In contrast, Differential Privacy reliably prevents memorization in our experiments, despite its computational and model-performance costs.
翻译:语言模型被广泛用于为用户产品提供自动文本完成服务,然而,最近的研究表明,语言模型(特别是大型模型)具有记住私人培训数据的巨大风险,而私人培训数据则容易被对手泄漏和抽取。在本研究中,我们测试一系列隐私保护技术的功效,以减轻敏感用户文本意外的记忆化,而其他因素,如模型大小和对抗条件等。我们测试“超常”减缓(没有正式隐私保障)和差异私人培训,以某种模型性能为代价提供可辨的隐私水平。我们的实验显示,(L2正规化除外),超常缓解措施在防止测试套件中的记忆化方面基本上没有效果,这可能是因为它们对定义“敏感”或“私人”文本的特征的假设过于强烈。相比之下,差异隐私可靠地防止了我们实验中的记忆化,尽管其计算和模型性能成本很高。