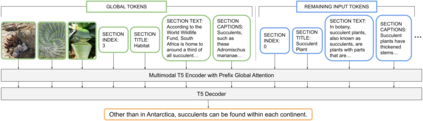
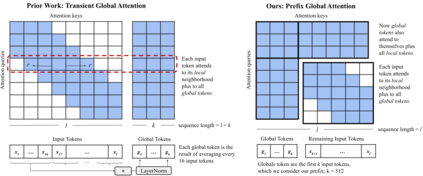
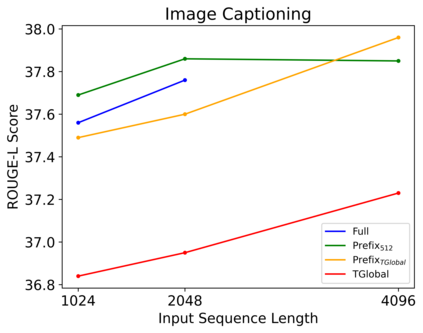
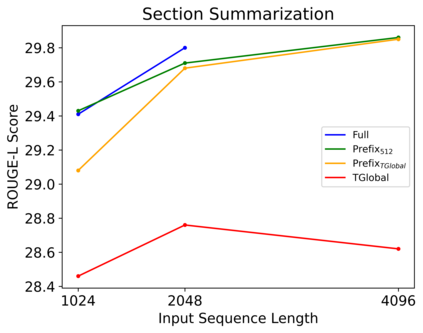
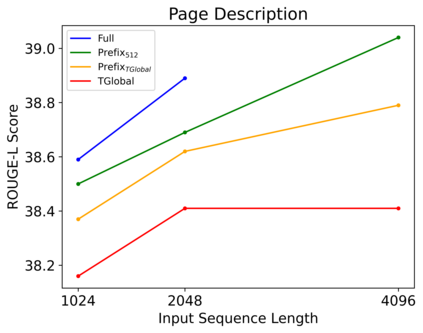
Webpages have been a rich, scalable resource for vision-language and language only tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data left underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage suite (WikiWeb2M) of 2M pages. We verify its utility on three generative tasks: page description generation, section summarization, and contextual image captioning. We design a novel attention mechanism Prefix Global, which selects the most relevant image and text content as global tokens to attend to the rest of the webpage for context. By using page structure to separate such tokens, it performs better than full attention with lower computational complexity. Experiments show that the new annotations from WikiWeb2M improve task performance compared to data from prior work. We also include ablations on sequence length, input features, and model size.
翻译:暂无翻译