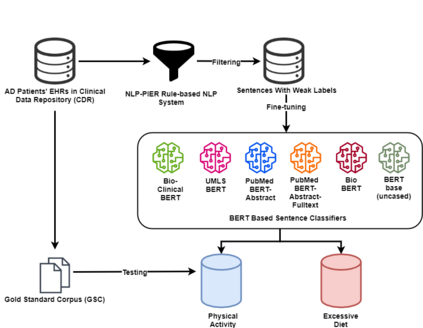
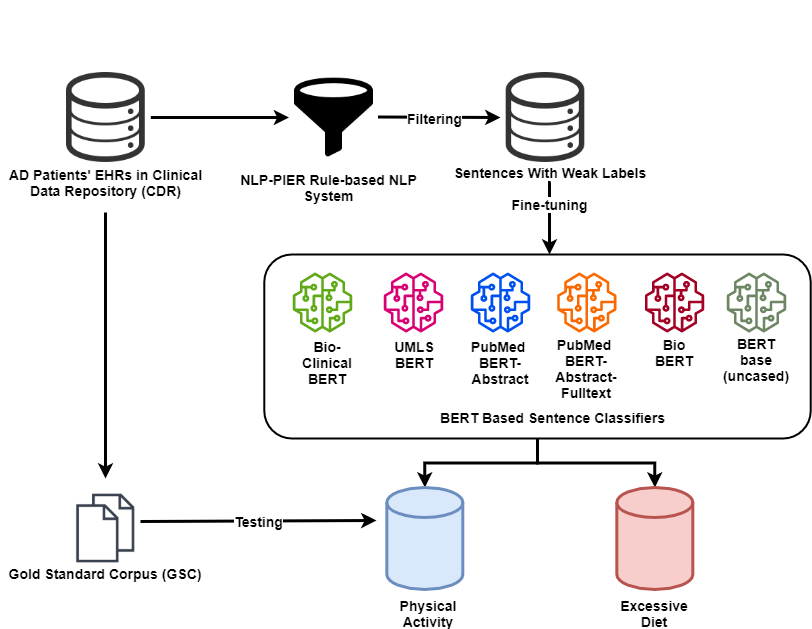
Since no effective therapies exist for Alzheimer's disease (AD), prevention has become more critical through lifestyle factor changes and interventions. Analyzing electronic health records (EHR) of patients with AD can help us better understand lifestyle's effect on AD. However, lifestyle information is typically stored in clinical narratives. Thus, the objective of the study was to demonstrate the feasibility of natural language processing (NLP) models to classify lifestyle factors (e.g., physical activity and excessive diet) from clinical texts. We automatically generated labels for the training data by using a rule-based NLP algorithm. We conducted weak supervision for pre-trained Bidirectional Encoder Representations from Transformers (BERT) models on the weakly labeled training corpus. These models include the BERT base model, PubMedBERT(abstracts + full text), PubMedBERT(only abstracts), Unified Medical Language System (UMLS) BERT, Bio BERT, and Bio-clinical BERT. We performed two case studies: physical activity and excessive diet, in order to validate the effectiveness of BERT models in classifying lifestyle factors for AD. These models were compared on the developed Gold Standard Corpus (GSC) on the two case studies. The PubmedBERT(Abs) model achieved the best performance for physical activity, with its precision, recall, and F-1 scores of 0.96, 0.96, and 0.96, respectively. Regarding classifying excessive diet, the Bio BERT model showed the highest performance with perfect precision, recall, and F-1 scores. The proposed approach leveraging weak supervision could significantly increase the sample size, which is required for training the deep learning models. The study also demonstrates the effectiveness of BERT models for extracting lifestyle factors for Alzheimer's disease from clinical notes.
翻译:由于对阿尔茨海默氏病(AD)没有有效的治疗方法,因此,通过生活方式因素的变化和干预,预防已变得更加重要。分析AD病人的电子健康记录(EHR)有助于我们更好地了解生活方式对AD的影响。然而,生活方式信息通常储存在临床叙述中。因此,研究的目的是证明自然语言处理模式的可行性,以便从临床文本中分类生活方式因素(例如,体育活动和过量饮食)。我们通过使用基于规则的NLP算法,自动为培训数据制作标签。我们对来自变压器(BERT)的预先培训双向电解码显示模型(EECD)对高标签的模型进行薄弱的监管,这些模型包括BERT的基础模型、PubMERT(摘要+全文)、PubMedBERT(仅摘要)、统一医学语言系统(UMLS)BERT、生物模型模型BERT和生物临床BERT。我们进行了两项案例研究:物理活动和过量饮食研究,以便验证BERERER模型在将FERS的精确度指标分类中进行两次测试的成绩分析,这些模型显示其最精确性研究。