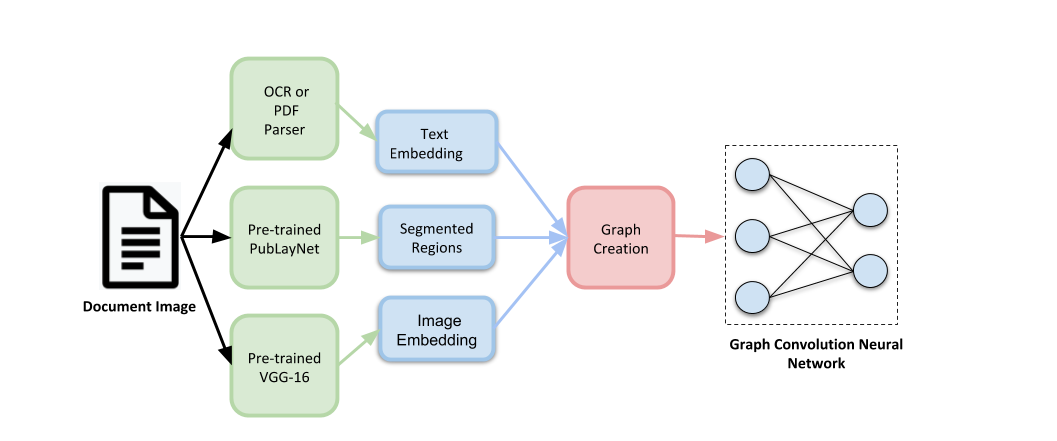
Document image classification remains a popular research area because it can be commercialized in many enterprise applications across different industries. Recent advancements in large pre-trained computer vision and language models and graph neural networks has lent document image classification many tools. However using large pre-trained models usually requires substantial computing resources which could defeat the cost-saving advantages of automatic document image classification. In the paper we propose an efficient document image classification framework that uses graph convolution neural networks and incorporates textual, visual and layout information of the document. We have rigorously benchmarked our proposed algorithm against several state-of-art vision and language models on both publicly available dataset and a real-life insurance document classification dataset. Empirical results on both publicly available and real-world data show that our methods achieve near SOTA performance yet require much less computing resources and time for model training and inference. This results in solutions than offer better cost advantages, especially in scalable deployment for enterprise applications. The results showed that our algorithm can achieve classification performance quite close to SOTA. We also provide comprehensive comparisons of computing resources, model sizes, train and inference time between our proposed methods and baselines. In addition we delineate the cost per image using our method and other baselines.
翻译:文件图像分类仍是一个广受欢迎的研究领域,因为在不同行业的许多企业应用中,文件图像分类可以商业化。在经过预先培训的大型计算机视觉和语言模型以及图形神经网络方面最近的进展为文件图像分类提供了许多工具。但是,使用经过培训的大型模型通常需要大量的计算资源,以挫败自动文件图像分类的节省成本优势。在文件中,我们建议了一个高效的文件图像分类框架,使用图象共线神经网络,并纳入文件的文字、视觉和布局信息。我们严格地将我们提议的算法与一些最新的视觉和语言模型基准基准基准进行了基准比较。我们还对公开可得的数据集和真实生命保险文件分类数据集中的一些最先进的视觉和语言模型进行了基准。关于公开和真实世界数据的经验性结果表明,我们的方法接近SOTA业绩,但需要更少的计算资源和时间进行模型培训和推算。这在解决方案上的结果比提供更好的成本优势,特别是在对企业应用的可缩放应用方面。结果表明,我们的算法可以实现与SOTA相当的分类性。我们还全面比较了计算资源、模型大小、培训和推算方法和其他基准之间的成本。