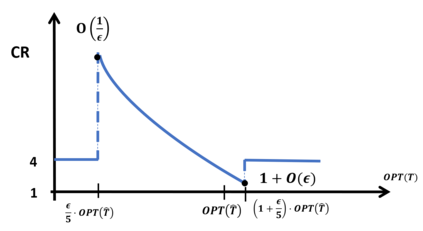
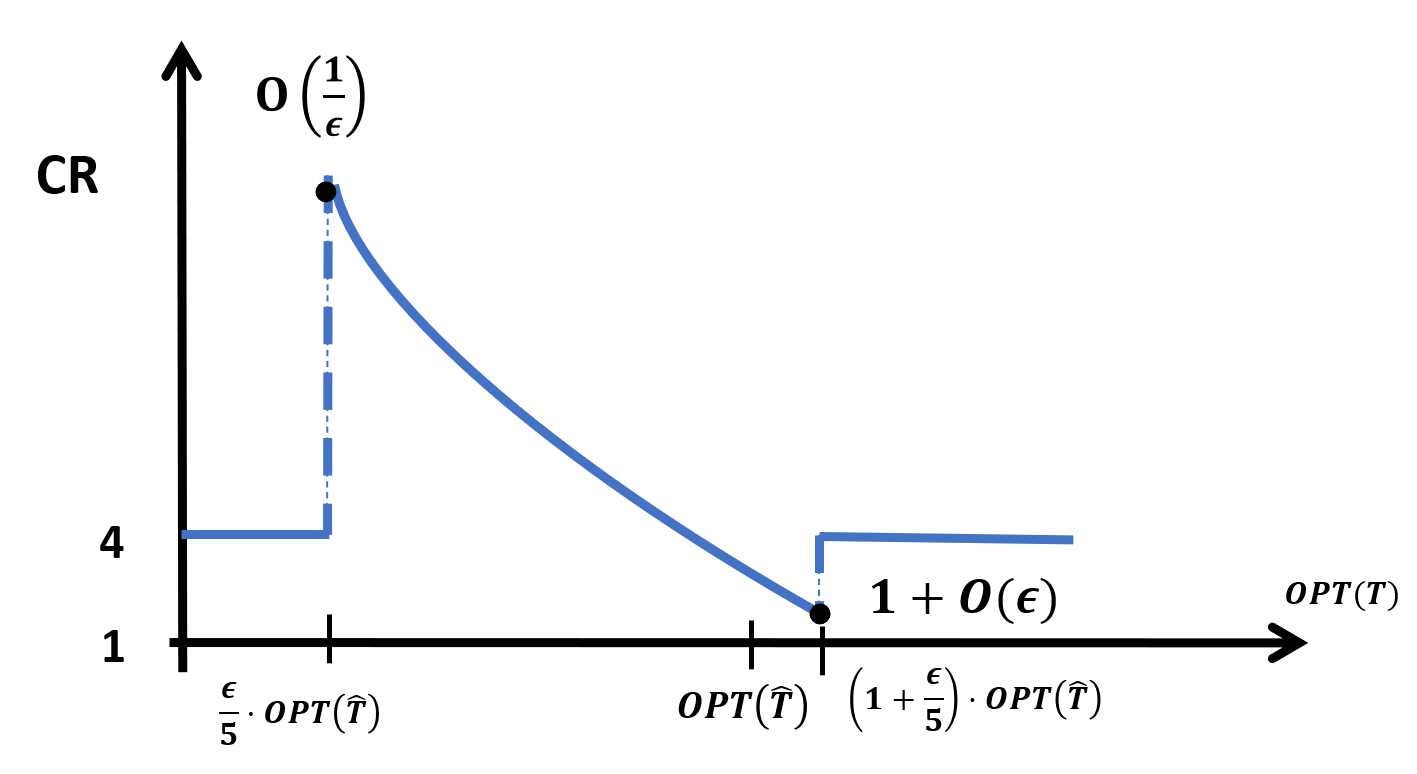
The emerging field of learning-augmented online algorithms uses ML techniques to predict future input parameters and thereby improve the performance of online algorithms. Since these parameters are, in general, real-valued functions, a natural approach is to use regression techniques to make these predictions. We introduce this approach in this paper, and explore it in the context of a general online search framework that captures classic problems like (generalized) ski rental, bin packing, minimum makespan scheduling, etc. We show nearly tight bounds on the sample complexity of this regression problem, and extend our results to the agnostic setting. From a technical standpoint, we show that the key is to incorporate online optimization benchmarks in the design of the loss function for the regression problem, thereby diverging from the use of off-the-shelf regression tools with standard bounds on statistical error.
翻译:新兴的学习强化在线算法领域使用 ML 技术来预测未来输入参数,从而改进在线算法的性能。 由于这些参数总的来说是真实价值的功能,因此自然的做法是使用回归技术来作出这些预测。 我们在本文件中引入了这种方法,并在一个总在线搜索框架的背景下探索了这一方法,它抓住了典型的(一般化的)滑雪租赁、垃圾包装、最小的黑板排程等典型问题。 我们对这一回归问题的样本复杂性表现出了近乎紧密的界限,并将我们的结果扩大到不可知的设置。 从技术角度看,我们表明关键在于将在线优化基准纳入回归问题损失函数的设计中,从而与使用带有统计错误标准界限的现成回归工具不同。