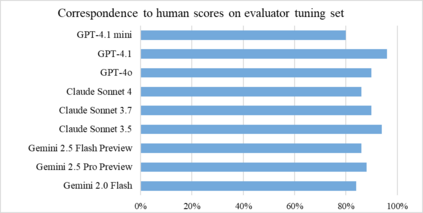
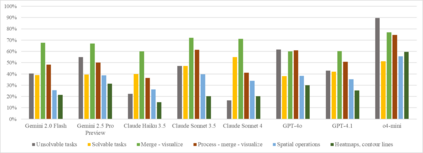
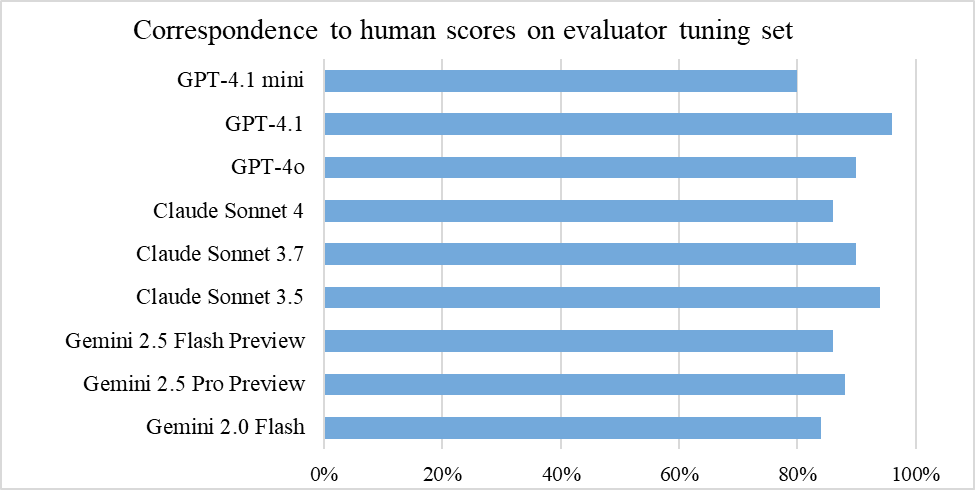
This paper establishes a benchmark for evaluating tool-calling capabilities of large language models (LLMs) on multi-step geospatial tasks relevant to commercial GIS practitioners. We assess eight commercial LLMs (Claude Sonnet 3.5 and 4, Claude Haiku 3.5, Gemini 2.0 Flash, Gemini 2.5 Pro Preview, GPT-4o, GPT-4.1 and o4-mini) using a simple tool-calling agent equipped with 23 geospatial functions. Our benchmark comprises tasks in four categories of increasing complexity, with both solvable and intentionally unsolvable tasks to test rejection accuracy. We develop a LLM-as-Judge evaluation framework to compare agent solutions against reference solutions. Results show o4-mini and Claude 3.5 Sonnet achieve the best overall performance, OpenAI's GPT-4.1, GPT-4o and Google's Gemini 2.5 Pro Preview do not fall far behind, but the last two are more efficient in identifying unsolvable tasks. Claude Sonnet 4, due its preference to provide any solution rather than reject a task, proved to be less accurate. We observe significant differences in token usage, with Anthropic models consuming more tokens than competitors. Common errors include misunderstanding geometrical relationships, relying on outdated knowledge, and inefficient data manipulation. The resulting benchmark set, evaluation framework, and data generation pipeline are released as open-source resources (available at https://github.com/Solirinai/GeoBenchX), providing one more standardized method for the ongoing evaluation of LLMs for GeoAI.
翻译:暂无翻译