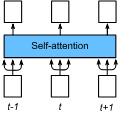
To improve the robustness of transformer neural networks used for temporal-dynamics prediction of chaotic systems, we propose a novel attention mechanism called easy attention which we demonstrate in time-series reconstruction and prediction. As a consequence of the fact that self attention only makes useof the inner product of queries and keys, it is demonstrated that the keys, queries and softmax are not necessary for obtaining the attention score required to capture long-term dependencies in temporal sequences. Through implementing singular-value decomposition (SVD) on the softmax attention score, we further observe that the self attention compresses contribution from both queries and keys in the spanned space of the attention score. Therefore, our proposed easy-attention method directly treats the attention scores as learnable parameters. This approach produces excellent results when reconstructing and predicting the temporal dynamics of chaotic systems exhibiting more robustness and less complexity than the self attention or the widely-used long short-term memory (LSTM) network. Our results show great potential for applications in more complex high-dimensional dynamical systems. Keywords: Machine Learning, Transformer, Self Attention, Koopman Operator, Chaotic System.
翻译:暂无翻译