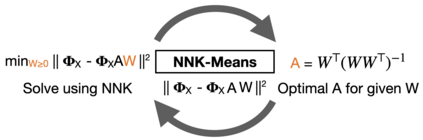
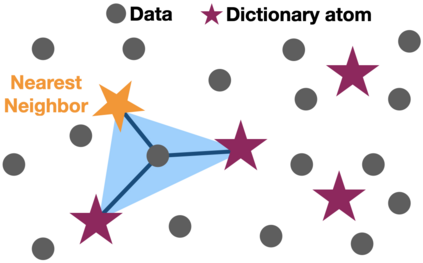
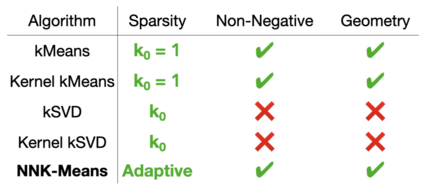
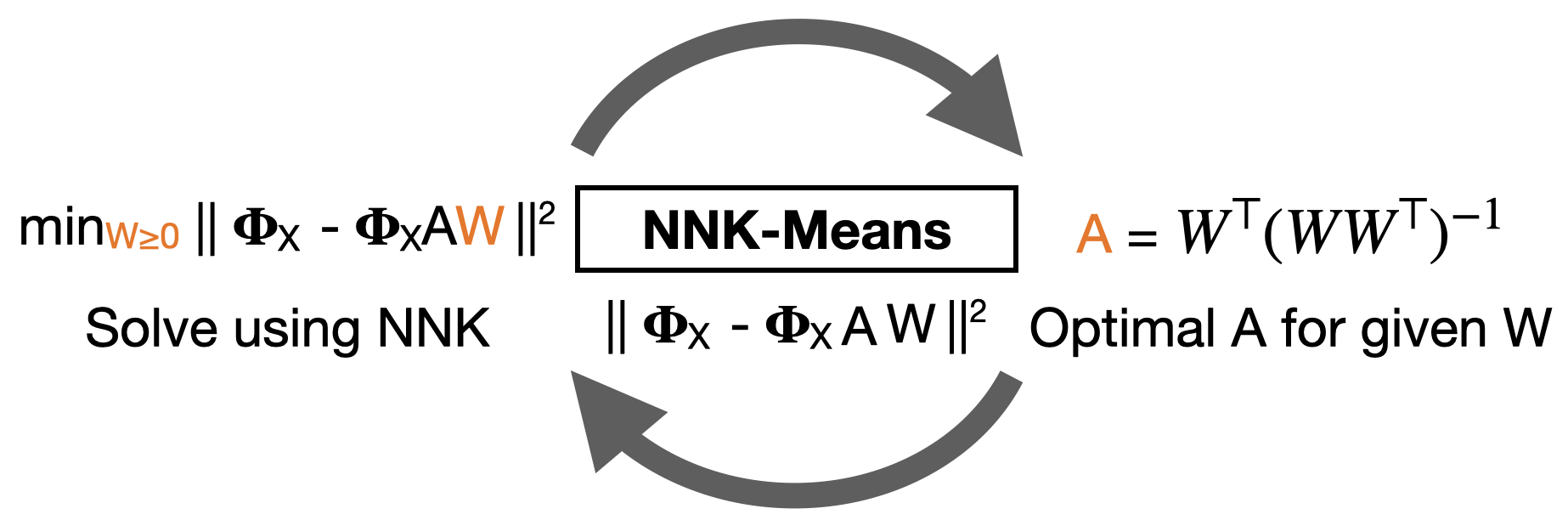
An increasing number of systems are being designed by first gathering significant amounts of data, and then optimizing the system parameters directly using the obtained data. Often this is done without analyzing the dataset structure. As task complexity, data size, and parameters all increase to millions or even billions, data summarization is becoming a major challenge. In this work, we investigate data summarization via dictionary learning, leveraging the properties of recently introduced non-negative kernel regression (NNK) graphs. Our proposed NNK-Means, unlike competing techniques, such askSVD, learns geometric dictionaries with atoms that lie in the input data space. Experiments show that summaries using NNK-Meanscan provide better discrimination compared to linear and kernel versions of kMeans and kSVD. Moreover, NNK-Means has a scalable implementation, with runtime complexity similar to that of kMeans.
翻译:通过首先收集大量数据,然后直接利用获得的数据优化系统参数,从而设计出越来越多的系统。 通常在不分析数据集结构的情况下这样做。 由于任务的复杂性、数据大小和参数都增加到数百万甚至数十亿,数据总和正在成为一个重大挑战。 在这项工作中,我们通过字典学习来调查数据总化,利用最近引入的非负内核回归图的特性。 我们提议的NNK-Means与相互竞争的技术不同,例如问SVD, 学习输入数据空间中的原子的几何词典。 实验显示,使用NNK-Meanscan的摘要比 kMeans 和 kSVD 的线性和内核版本提供了更好的区别。 此外, NNK-Means 具有可缩放的功能,运行时间的复杂性类似于 kMeans 。