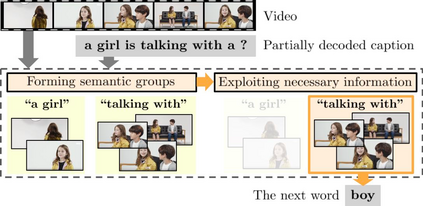
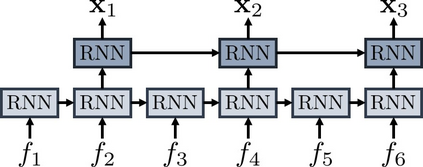
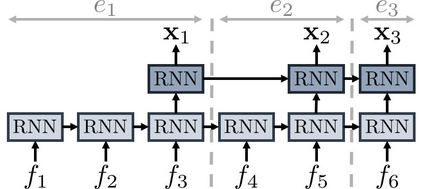
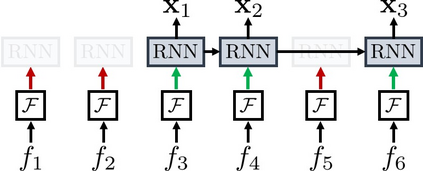
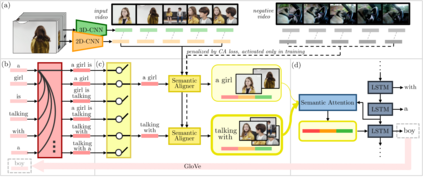
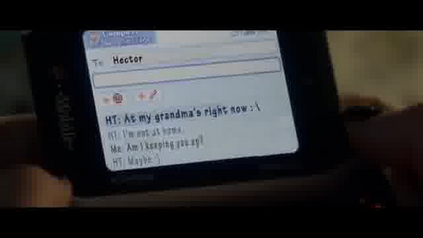
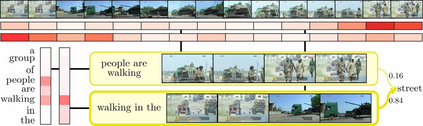
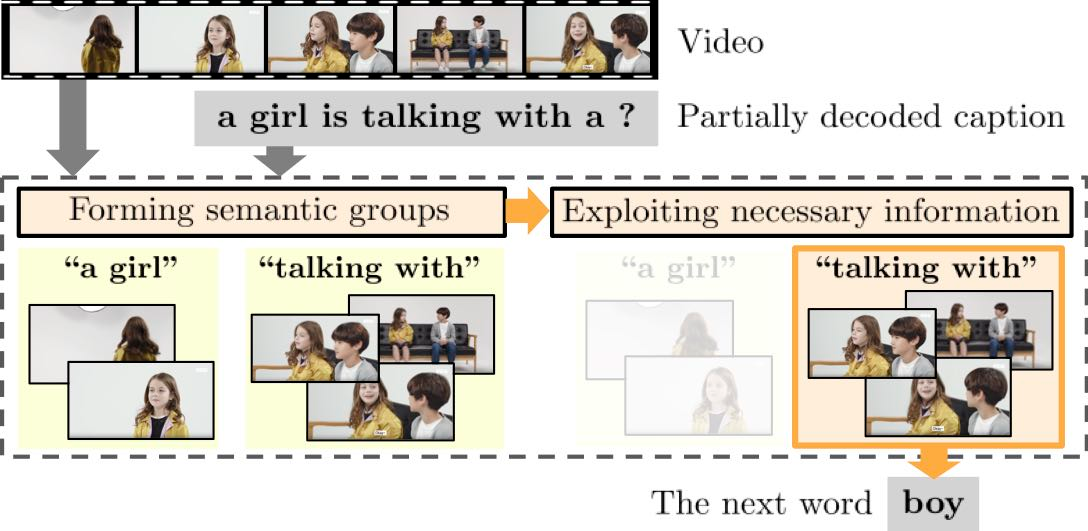
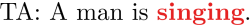This paper considers a video caption generating network referred to as Semantic Grouping Network (SGN) that attempts (1) to group video frames with discriminating word phrases of partially decoded caption and then (2) to decode those semantically aligned groups in predicting the next word. As consecutive frames are not likely to provide unique information, prior methods have focused on discarding or merging repetitive information based only on the input video. The SGN learns an algorithm to capture the most discriminating word phrases of the partially decoded caption and a mapping that associates each phrase to the relevant video frames - establishing this mapping allows semantically related frames to be clustered, which reduces redundancy. In contrast to the prior methods, the continuous feedback from decoded words enables the SGN to dynamically update the video representation that adapts to the partially decoded caption. Furthermore, a contrastive attention loss is proposed to facilitate accurate alignment between a word phrase and video frames without manual annotations. The SGN achieves state-of-the-art performances by outperforming runner-up methods by a margin of 2.1%p and 2.4%p in a CIDEr-D score on MSVD and MSR-VTT datasets, respectively. Extensive experiments demonstrate the effectiveness and interpretability of the SGN.
翻译:本文考虑一个视频字幕生成网络,称为“语义组网”,它试图(1) 将视频框架与部分解码标题的歧视性词句组合在一起,然后(2) 在预测下一个字词时解码这些语义一致的组。由于连续框架不可能提供独特的信息,先前的方法侧重于抛弃或合并仅以输入视频为基础的重复信息。SGN学习一种算法,以捕捉部分解码标题中最有区别的词句,并绘制一种将每个词句与有关视频框架联系起来的绘图——建立这一绘图可以将语义相关的框架集中起来,从而减少冗余力。与以前的方法不同,解码词组的连续反馈使SGN能够动态更新视频表述,使其适应部分解码标题。此外,还提议了对比性关注损失,以便于在没有人工说明的情况下对一个词句和视频框架进行准确的校正一致。 SGNB通过2.1%和2.4%的比差分法,在CIDERMS-D测试中,分别展示了MSVS-D的M-D 和MVSD的M-Crediversiality 和MVD的MValalality 。