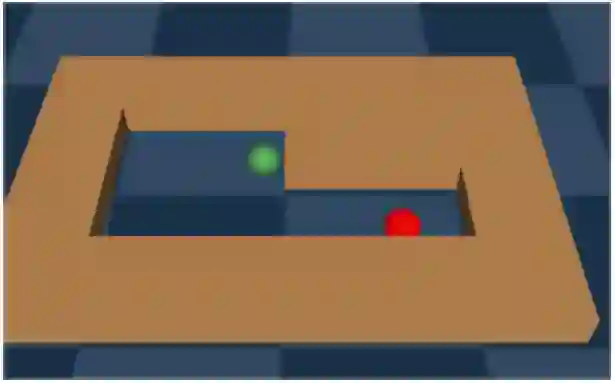
We address the challenge of offline reinforcement learning using realistic data, specifically non-expert data collected through sub-optimal behavior policies. Under such circumstance, the learned policy must be safe enough to manage \textit{distribution shift} while maintaining sufficient flexibility to deal with non-expert (bad) demonstrations from offline data.To tackle this issue, we introduce a novel method called Outcome-Driven Action Flexibility (ODAF), which seeks to reduce reliance on the empirical action distribution of the behavior policy, hence reducing the negative impact of those bad demonstrations.To be specific, a new conservative reward mechanism is developed to deal with {\it distribution shift} by evaluating actions according to whether their outcomes meet safety requirements - remaining within the state support area, rather than solely depending on the actions' likelihood based on offline data.Besides theoretical justification, we provide empirical evidence on widely used MuJoCo and various maze benchmarks, demonstrating that our ODAF method, implemented using uncertainty quantification techniques, effectively tolerates unseen transitions for improved "trajectory stitching," while enhancing the agent's ability to learn from realistic non-expert data.
翻译:暂无翻译