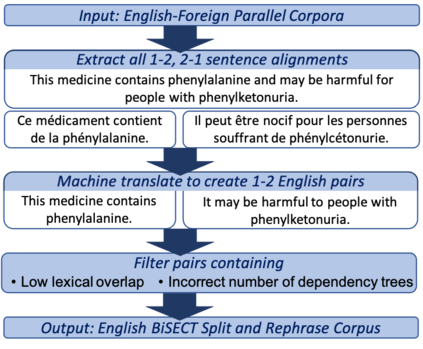
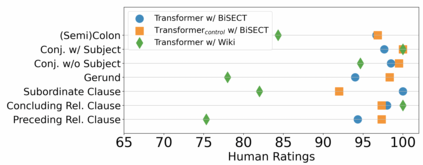
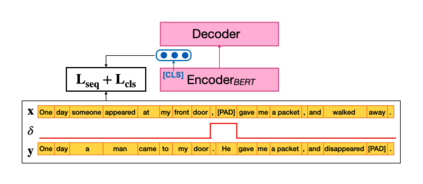
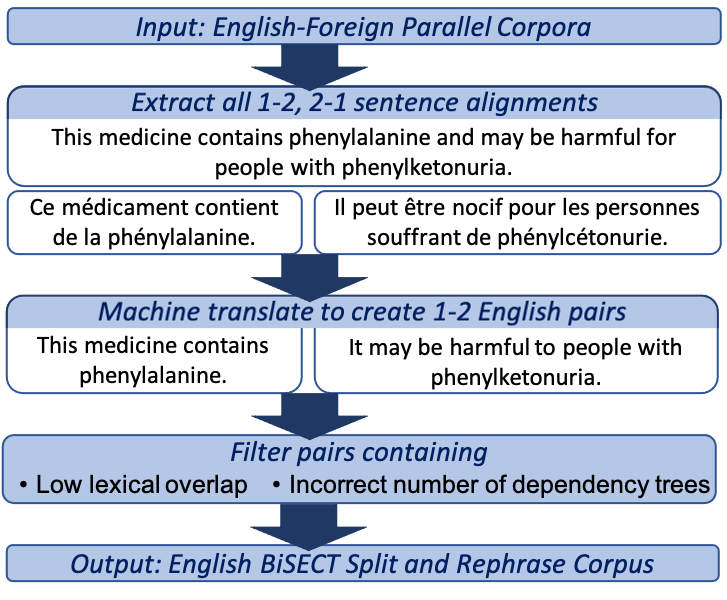
An important task in NLP applications such as sentence simplification is the ability to take a long, complex sentence and split it into shorter sentences, rephrasing as necessary. We introduce a novel dataset and a new model for this `split and rephrase' task. Our BiSECT training data consists of 1 million long English sentences paired with shorter, meaning-equivalent English sentences. We obtain these by extracting 1-2 sentence alignments in bilingual parallel corpora and then using machine translation to convert both sides of the corpus into the same language. BiSECT contains higher quality training examples than previous Split and Rephrase corpora, with sentence splits that require more significant modifications. We categorize examples in our corpus, and use these categories in a novel model that allows us to target specific regions of the input sentence to be split and edited. Moreover, we show that models trained on BiSECT can perform a wider variety of split operations and improve upon previous state-of-the-art approaches in automatic and human evaluations.
翻译:简化刑期等NLP应用中的一项重要任务,如简化刑期,是能够使用长而复杂的刑期,将其分成较短的刑期,必要时进行改写。我们为这项“分解和改写”任务引入了新的数据集和新模式。我们的BiSECT培训数据包括100万长的英语句子,配有较短的、意义相等的英语句子。我们通过在双语平行的平行公司中提取1-2个句子对齐,然后用机器翻译将保护令的两侧转换为同一语言来获得这些内容。BISECT包含比以往的分解和改写法更高质量的培训实例,并配有需要更重大修改的句子。我们在我们的文库中将实例分类,并将这些类别用在一个新的模型中,使我们能够针对投入句中要分开和编辑的特定区域。此外,我们展示了在BisECT培训的模型可以进行更多样化的分解操作,并改进以前在自动和人文评价中采用的最新方法。