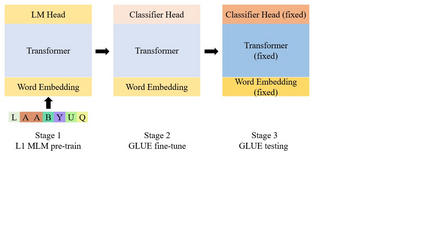
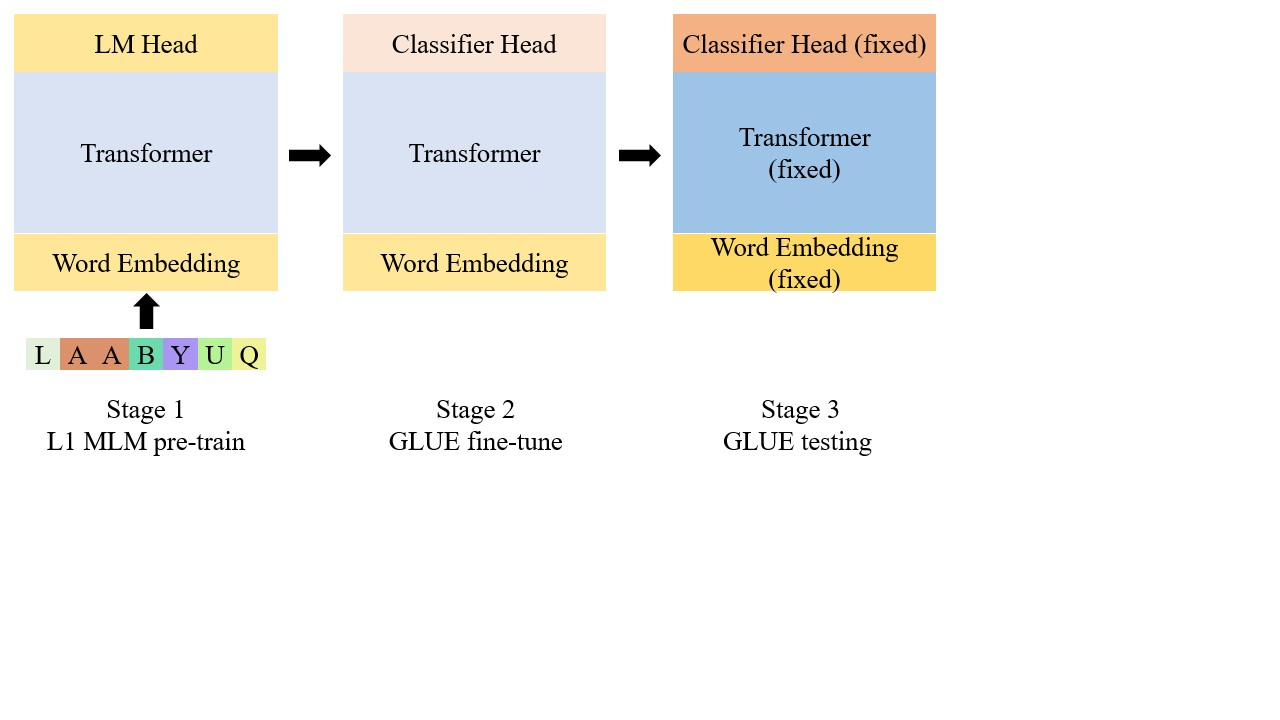
In this paper, we study how the intrinsic nature of pre-training data contributes to the fine-tuned downstream performance. To this end, we pre-train different transformer-based masked language models on several corpora with certain features, and we fine-tune those language models on GLUE benchmarks. We find that models pre-trained on unstructured data beat those trained directly from scratch on downstream tasks. Our results also show that pre-training on structured data does not always make the model acquire ability that can be transferred to natural language downstream tasks. To our great astonishment, we uncover that pre-training on certain non-human language data gives GLUE performance close to performance pre-trained on another non-English language.
翻译:在本文中,我们研究训练前数据的内在性质如何有助于细微调整下游业绩。为此,我们预先对几个具有某些特点的公司进行了不同变压器蒙面语言模型的培训,并对GLUE基准进行了微调。我们发现,在非结构化数据方面接受过预先培训的模型可以直接从零到零地击败那些受过训练的人完成下游任务。我们的结果还表明,关于结构化数据的预先培训并不总是使模型获得能力,可以转移到自然语言下游任务。对于我们伟大的惊奇,我们发现,关于某些非人类语言数据的培训前,GLUE的性能接近于对另一种非英语语言进行预先培训的性能。