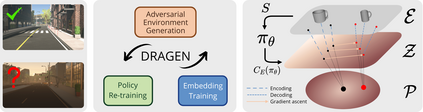
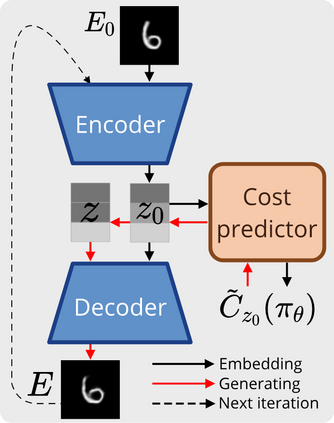
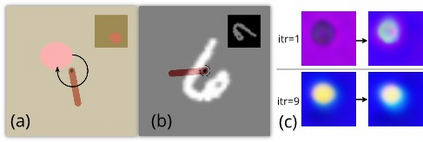
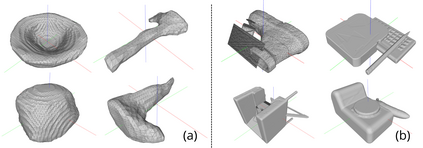
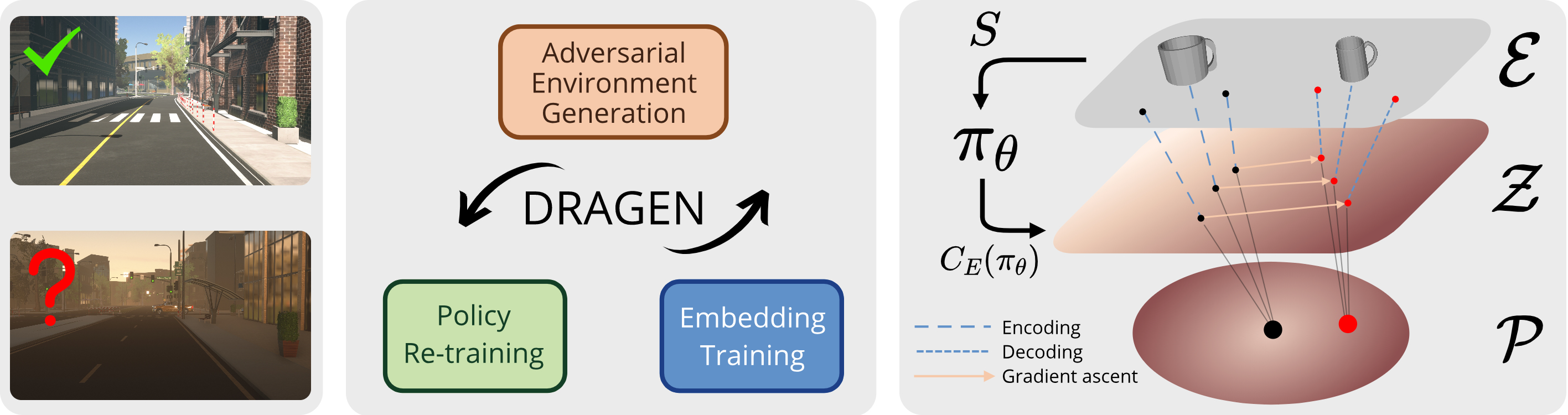
Our goal is to train control policies that generalize well to unseen environments. Inspired by the Distributionally Robust Optimization (DRO) framework, we propose DRAGEN - Distributionally Robust policy learning via Adversarial Generation of ENvironments - for iteratively improving robustness of policies to realistic distribution shifts by generating adversarial environments. The key idea is to learn a generative model for environments whose latent variables capture cost-predictive and realistic variations in environments. We perform DRO with respect to a Wasserstein ball around the empirical distribution of environments by generating realistic adversarial environments via gradient ascent on the latent space. We demonstrate strong Out-of-Distribution (OoD) generalization in simulation for (i) swinging up a pendulum with onboard vision and (ii) grasping realistic 3D objects. Grasping experiments on hardware demonstrate better sim2real performance compared to domain randomization.
翻译:我们的目标是,在分布式强力优化(DRO)框架的启发下,我们建议DRAGEN - 通过环境的反向生成来进行分布式强力政策学习,通过创造对抗环境,迭代地提高政策的稳健性,使分配变化符合现实。关键思想是学习一个潜在变量捕捉环境成本预测和现实变化的环境的基因模型。我们用瓦塞斯坦球围绕环境的经验性分布进行DRO,通过潜在空间的梯度生成现实的对抗性环境。我们在模拟中展示了强烈的外向扩散(OOD)一般化,以便(一) 移动机上视觉的弹孔和(二) 掌握现实的 3D 对象。在硬件上进行实验表明比域随机化更好的模拟性功能。