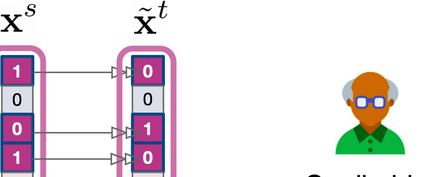
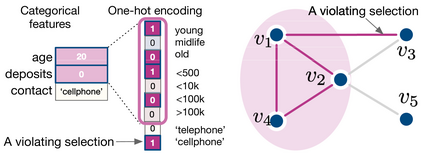
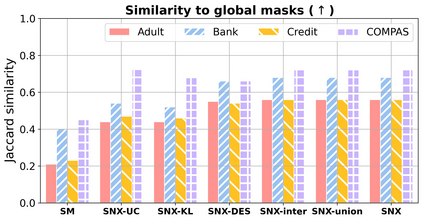
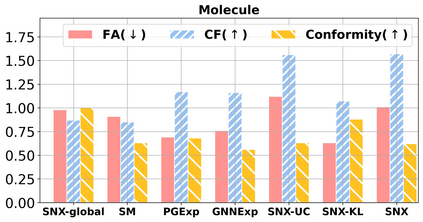
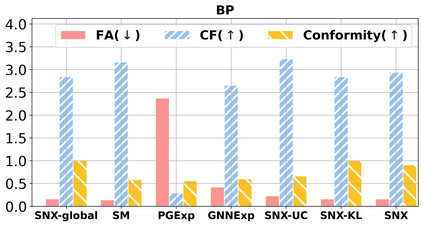
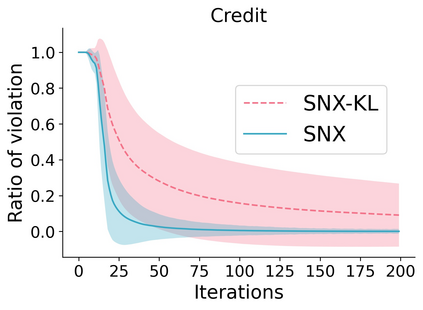
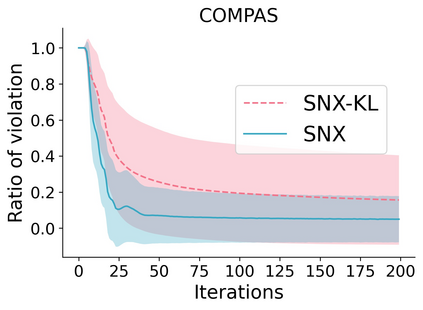
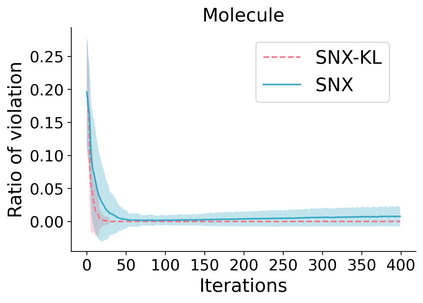
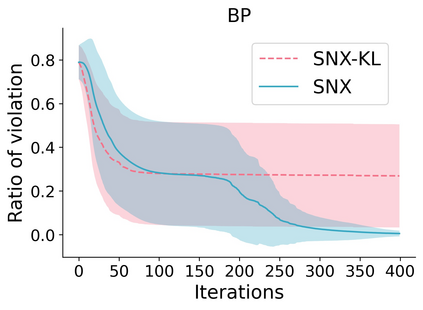
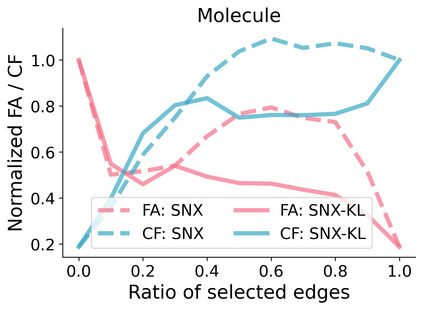
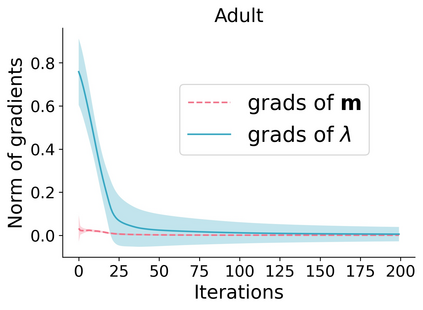
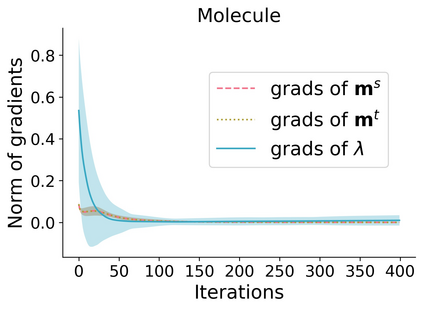
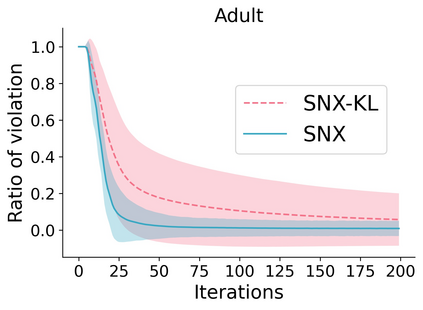
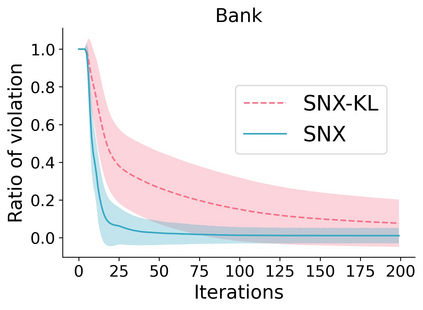
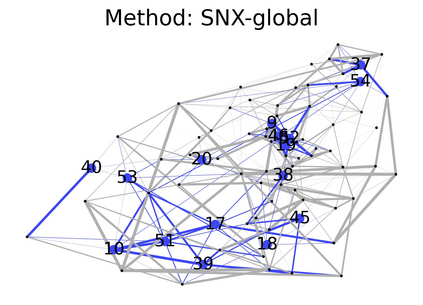
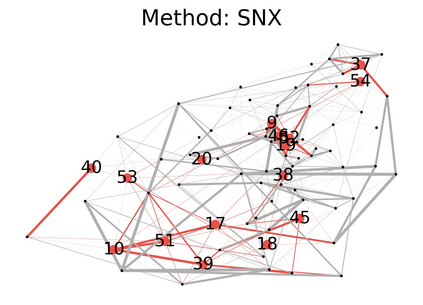
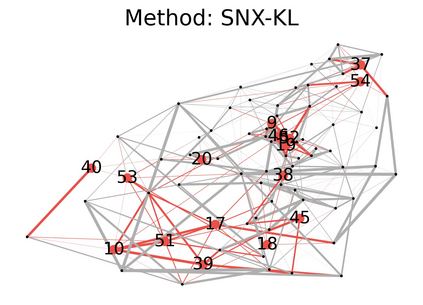
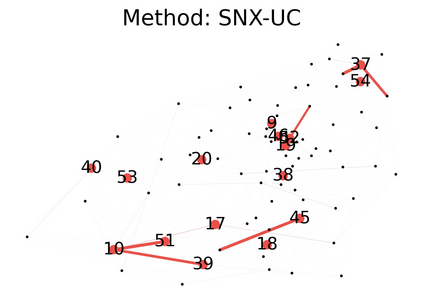
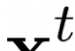Learning to compare two objects are essential in applications, such as digital forensics, face recognition, and brain network analysis, especially when labeled data is scarce and imbalanced. As these applications make high-stake decisions and involve societal values like fairness and transparency, it is critical to explain the learned models. We aim to study post-hoc explanations of Siamese networks (SN) widely used in learning to compare. We characterize the instability of gradient-based explanations due to the additional compared object in SN, in contrast to architectures with a single input instance. We propose an optimization framework that derives global invariance from unlabeled data using self-learning to promote the stability of local explanations tailored for specific query-reference pairs. The optimization problems can be solved using gradient descent-ascent (GDA) for constrained optimization, or SGD for KL-divergence regularized unconstrained optimization, with convergence proofs, especially when the objective functions are nonconvex due to the Siamese architecture. Quantitative results and case studies on tabular and graph data from neuroscience and chemical engineering show that the framework respects the self-learned invariance while robustly optimizing the faithfulness and simplicity of the explanation. We further demonstrate the convergence of GDA experimentally.
翻译:在数字法证、面部识别和大脑网络分析等应用中,学习比较两个对象至关重要,在数字法证、面部识别和大脑网络分析等应用中,尤其是在标签数据稀缺和不平衡的情况下,尤其当标签数据稀缺和不平衡时,这些应用作出高度决策并涉及公平和透明的社会价值观,因此,解释学习模式至关重要。我们的目标是研究在学习时广泛使用的Siamses网络(SN)的热后解释。我们把基于梯度的解释的不稳定性归因于SAN的额外比较对象,与单一输入实例相对应。我们提议了一个优化框架,利用自学方法从未贴标签数据中获取全球差异性数据,以促进适合具体查询对应对象的本地解释的稳定性。优化问题可以通过梯度下降偏好优化(GDA)或SGD(SGD)来解决,以便限制优化,或SGDM(SG)来进行常规的不松紧的优化,同时提供趋同证据,特别是在目标功能因Siamesi结构不相交的情况下,我们提议了一个优化结果和对神经科学和化学工程的表和图表数据进行个案研究,从中得出全球差异分析的结果和案例研究,表明框架在实验性解释方面进一步尊重自我学习的简单性。