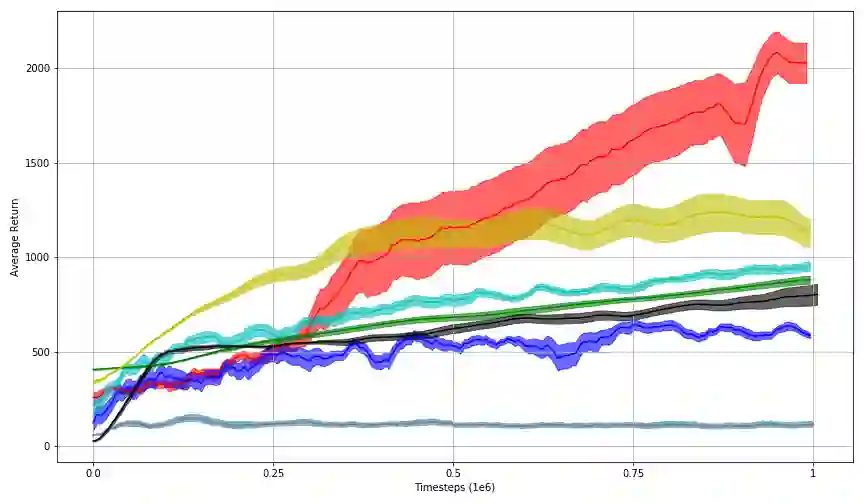
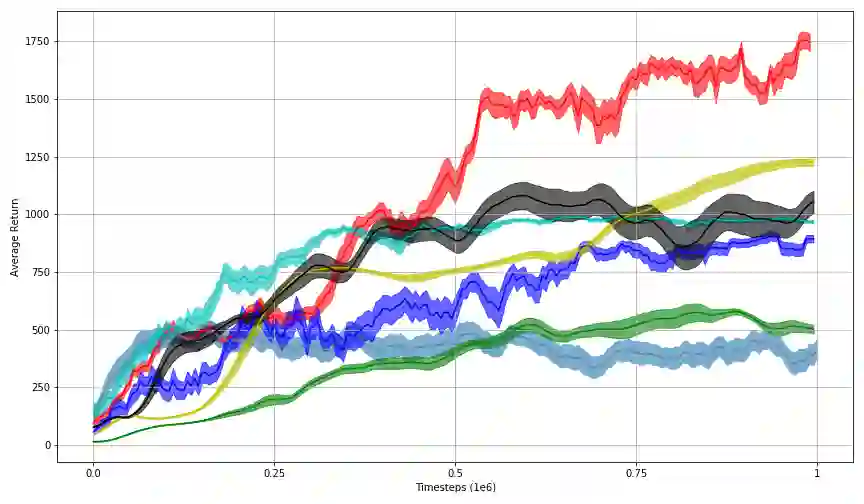
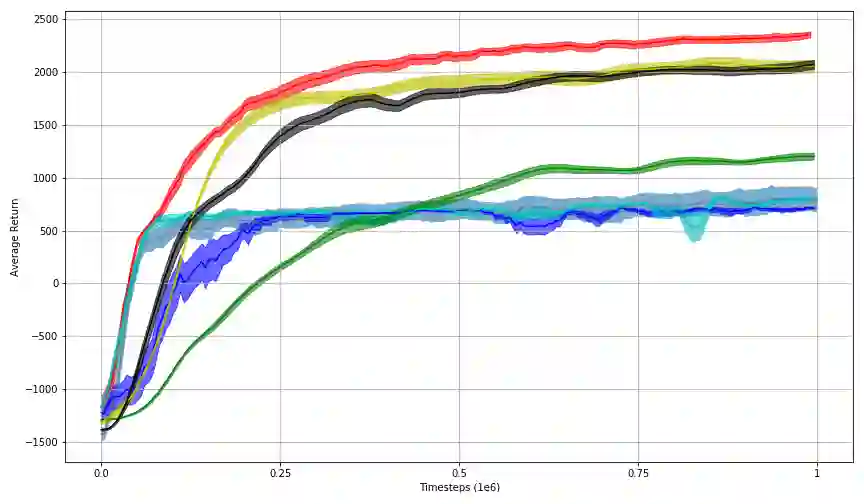
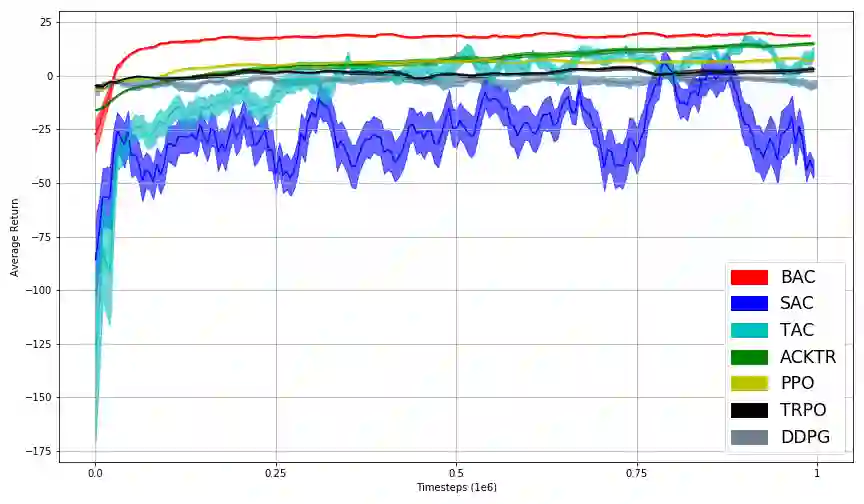
In this work, we propose Behavior-Guided Actor-Critic (BAC), an off-policy actor-critic deep RL algorithm. BAC mathematically formulates the behavior of the policy through autoencoders by providing an accurate estimation of how frequently each state-action pair was visited while taking into consideration state dynamics that play a crucial role in determining the trajectories produced by the policy. The agent is encouraged to change its behavior consistently towards less-visited state-action pairs while attaining good performance by maximizing the expected discounted sum of rewards, resulting in an efficient exploration of the environment and good exploitation of all high reward regions. One prominent aspect of our approach is that it is applicable to both stochastic and deterministic actors in contrast to maximum entropy deep reinforcement learning algorithms. Results show considerably better performances of BAC when compared to several cutting-edge learning algorithms.
翻译:在这项工作中,我们建议Bahavior-Guided Actor-Critic(BAC),这是一种不受政策约束的行为者-批评深度RL算法(BAC),BAC数学地通过自动校对者来制定政策行为,准确估计每个州对方访问的频率,同时考虑到在确定政策产生的轨迹方面发挥关键作用的州动态。鼓励代理人不断改变其行为,将其行为转变为不那么受监督的州对方,同时通过尽量扩大预期的折扣奖励总和来取得良好的业绩,从而有效地探索环境,并对所有高报酬地区进行良好的利用。我们方法的一个突出方面是,它既适用于随机和确定性行为者,又适用于最大程度的酶深强化学习算法。结果显示,与一些尖端学习算法相比,BAC的表现要好得多。